[點晴永久免費OA]巨細!Python爬蟲詳解
導(dǎo)讀:爬蟲(又稱為網(wǎng)頁蜘蛛,網(wǎng)絡(luò)機器人,在 FOAF 社區(qū)中間,更經(jīng)常的稱為網(wǎng)頁追逐者);它是一種按照一定的規(guī)則,自動地抓取網(wǎng)絡(luò)信息的程序或者腳本。 作者:潮汐 來源:Python 技術(shù)「ID: pythonall」  如果我們把互聯(lián)網(wǎng)比作一張大的蜘蛛網(wǎng),那一臺計算機上的數(shù)據(jù)便是蜘蛛網(wǎng)上的一個獵物,而爬蟲程序就是一只小蜘蛛,他們沿著蜘蛛網(wǎng)抓取自己想要的獵物/數(shù)據(jù)。 01 爬蟲的基本流程 02 網(wǎng)頁的請求與響應(yīng)網(wǎng)頁的請求和響應(yīng)方式是 Request 和 Response。
瀏覽器在接收 Response 后,會解析其內(nèi)容來顯示給用戶,而爬蟲程序在模擬瀏覽器發(fā)送請求然后接收 Response 后,是要提取其中的有用數(shù)據(jù)。 1. 發(fā)起請求:Request請求的發(fā)起是使用 http 庫向目標站點發(fā)起請求,即發(fā)送一個Request。 Request對象的作用是與客戶端交互,收集客戶端的 Form、Cookies、超鏈接,或者收集服務(wù)器端的環(huán)境變量。 Request 對象是從客戶端向服務(wù)器發(fā)出請求,包括用戶提交的信息以及客戶端的一些信息。客戶端可通過 HTML 表單或在網(wǎng)頁地址后面提供參數(shù)的方法提交數(shù)據(jù)。 然后服務(wù)器通過 request 對象的相關(guān)方法來獲取這些數(shù)據(jù)。request 的各種方法主要用來處理客戶端瀏覽器提交的請求中的各項參數(shù)和選項。 Request 包含:請求 URL、請求頭、請求體等。
一般做爬蟲都會加上請求頭。 例如:抓取百度網(wǎng)址的數(shù)據(jù)請求信息如下: 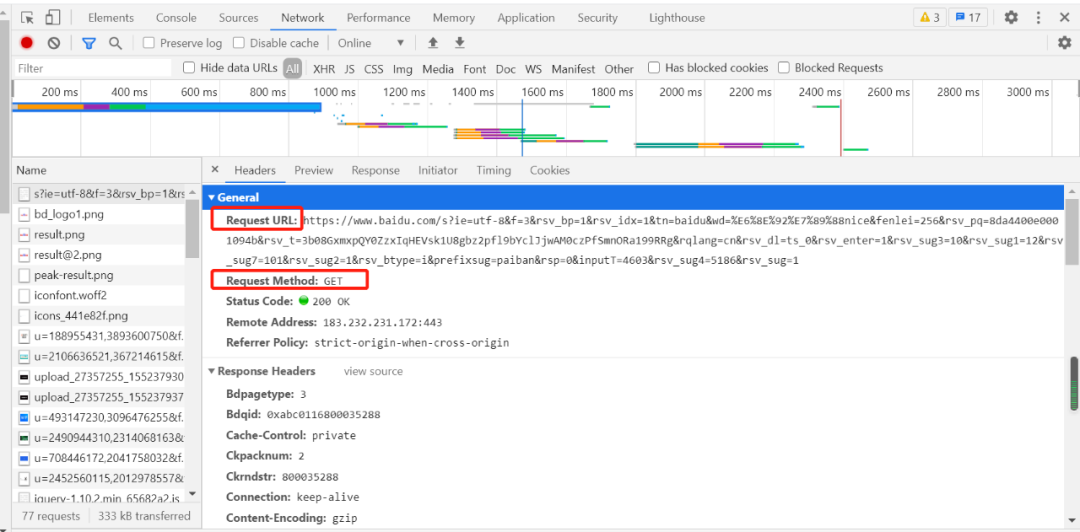 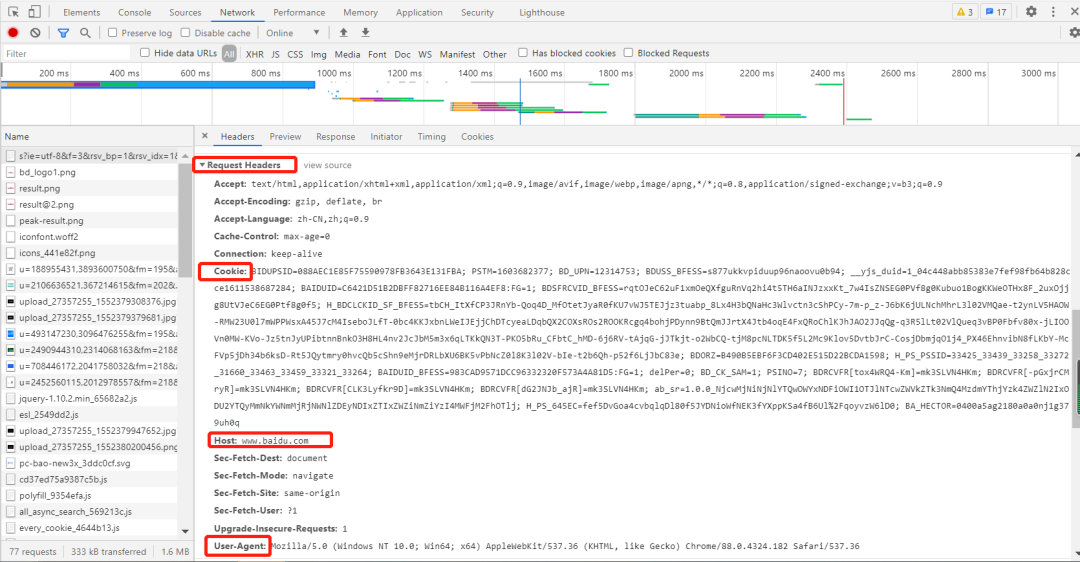 2. 獲取響應(yīng)內(nèi)容爬蟲程序在發(fā)送請求后,如果服務(wù)器能正常響應(yīng),則會得到一個Response,即響應(yīng)。 Response 信息包含:html、json、圖片、視頻等,如果沒報錯則能看到網(wǎng)頁的基本信息。例如:一個的獲取網(wǎng)頁響應(yīng)內(nèi)容程序如下: import requests request_headers={ 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9', 'Cookie': 'BIDUPSID=088AEC1E85F75590978FB3643E131FBA; PSTM=1603682377; BD_UPN=12314753; BDUSS_BFESS=s877ukkvpiduup96naoovu0b94; __yjs_duid=1_04c448abb85383e7fef98fb64b828cce1611538687284; BAIDUID=C6421D51B2DBFF82716EE84B116A4EF8:FG=1; BDSFRCVID_BFESS=rqtOJeC62uF1xmOeQXfguRnVq2hi4t5TH6aINJzxxKt_7w4IsZNSEG0PVf8g0Kubuo1BogKKWeOTHx8F_2uxOjjg8UtVJeC6EG0Ptf8g0f5; H_BDCLCKID_SF_BFESS=tbCH_ItXfCP3JRnYb-Qoq4D_MfOtetJyaR0fKU7vWJ5TEJjz3tuabp_8Lx4H3bQNaHc3Wlvctn3cShPCy-7m-p_z-J6bK6jULNchMhrL3l02VMQae-t2ynLV5HAOW-RMW23U0l7mWPPWsxA45J7cM4IseboJLfT-0bc4KKJxbnLWeIJEjjChDTcyeaLDqbQX2COXsROs2ROOKRcgq4bohjPDynn9BtQmJJrtX4Jtb4oqE4FxQRoChlKJhJAO2JJqQg-q3R5lLt02VlQueq3vBP0Fbfv80x-jLIOOVn0MW-KVo-Jz5tnJyUPibtnnBnkO3H8HL4nv2JcJbM5m3x6qLTKkQN3T-PKO5bRu_CFbtC_hMD-6j6RV-tAjqG-jJTkjt-o2WbCQ-tjM8pcNLTDK5f5L2Mc9Klov5DvtbJrC-CosjDbmjqO1j4_PX46EhnvibN8fLKbY-McFVp5jDh34b6ksD-Rt5JQytmry0hvcQb5cShn9eMjrDRLbXU6BK5vPbNcZ0l8K3l02V-bIe-t2b6Qh-p52f6LjJbC83e; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; H_PS_PSSID=33425_33439_33258_33272_31660_33463_33459_33321_33264; BAIDUID_BFESS=983CAD9571DCC96332320F573A4A81D5:FG=1; delPer=0; BD_CK_SAM=1; PSINO=7; BDRCVFR[tox4WRQ4-Km]=mk3SLVN4HKm; BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm; BDRCVFR[CLK3Lyfkr9D]=mk3SLVN4HKm; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; BD_HOME=1; H_PS_645EC=0c49V2LWy0d6V4FbFplBYiy6xyUu88szhVpw2raoJDgdtE3AL0TxHMUUFPM; BA_HECTOR=0l05812h21248584dc1g38qhn0r; COOKIE_SESSION=1_0_8_3_3_9_0_0_7_3_0_1_5365_0_3_0_1614047800_0_1614047797%7C9%23418111_17_1611988660%7C5; BDSVRTM=1', 'Host':'www.baidu.com', 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36'} response = requests.get('https://www.baidu.com/s',params={'wd':'帥哥'},headers=request_headers) #params內(nèi)部就是調(diào)用urlencode print(response.text) 以上內(nèi)容輸出的就是網(wǎng)頁的基本信息,它包含 html、json、圖片、視頻等,如下圖所示:  Response 響應(yīng)后會返回一些響應(yīng)信息,例下: 1)響應(yīng)狀態(tài)
2)Respone header
3)preview 是網(wǎng)頁源代碼最主要的部分,包含了請求資源的內(nèi)容,如網(wǎng)頁html、圖片、二進制數(shù)據(jù)等 4)解析內(nèi)容
5)保存數(shù)據(jù)爬取的數(shù)據(jù)以文件的形式保存在本地或者直接將抓取的內(nèi)容保存在數(shù)據(jù)庫中,數(shù)據(jù)庫可以是 MySQL、Mongdb、Redis、Oracle 等…… 03 寫在最后爬蟲的總流程可以理解為:蜘蛛要抓某個獵物-->沿著蛛絲找到獵物-->吃到獵物;即爬取-->解析-->存儲。 在爬取數(shù)據(jù)過程中所需參考工具如下:
04 總結(jié)今天的文章是對爬蟲的原理做一個詳解,希望對大家有幫助,同時也在后面的工作中奠定基礎(chǔ)! 轉(zhuǎn)自:https://cloud.tencent.com/developer/article/1815295 該文章在 2024/1/16 9:35:26 編輯過 |
關(guān)鍵字查詢
相關(guān)文章
正在查詢... 的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國內(nèi)大量中小企業(yè)的青睞。")
主要針對港口碼頭集裝箱與散貨日常運作、調(diào)度、堆場、車隊、財務(wù)費用、相關(guān)報表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點,圍繞調(diào)度、堆場作業(yè)而開發(fā)的。集技術(shù)的先進性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
提供了貨物產(chǎn)品管理,銷售管理,采購管理,倉儲管理,倉庫管理,保質(zhì)期管理,貨位管理,庫位管理,生產(chǎn)管理,WMS管理系統(tǒng),標簽打印,條形碼,二維碼管理,批號管理軟件。")
都免費,不限功能、不限時間、不限用戶的免費OA協(xié)同辦公管理系統(tǒng)。")
|


 400 186 1886
400 186 1886
")

