select count (*) from articleselect * from article order by publish_time desc limit 0 ,20 這個(gè)操作是一般我們的常規(guī)分頁操作,先進(jìn)行total然后進(jìn)行分頁獲取,這種做法的好處是支持任意規(guī)則的分頁,缺點(diǎn)就是需要查詢兩次,一次count、一次limit,當(dāng)然后期數(shù)據(jù)量實(shí)在太大可以只需要第一次count,但是也有一個(gè)問題,就是如果數(shù)據(jù)量一直在變化,會(huì)出現(xiàn)下一次分頁中,還會(huì)有上一次的部分?jǐn)?shù)據(jù),因?yàn)閿?shù)據(jù)在不斷地新增,你的分頁沒跟上發(fā)布的速度那么就會(huì)有這個(gè)情況發(fā)生。
瀑布流分頁
除了上述常規(guī)分頁操作外,我們針對(duì)特定順序的分頁也可以進(jìn)行特定的分頁方式來實(shí)現(xiàn)高性能,因?yàn)榛诖笄疤嵛覀兪谴髷?shù)量下的瀑布流,我們的文章假設(shè)是以雪花id作為主鍵,那么我們的分頁可以這么寫:
select * from article where id <last_id order by publish_time desc limit 0 ,20 首先我們來分析一下,這個(gè)語句是利用了插入的數(shù)據(jù)分布是順序和你需要查詢的排序一致來實(shí)現(xiàn)的,又因?yàn)閕d不會(huì)重復(fù),并且雪花id的順序和時(shí)間是一致的都是同向的,所以可以利用這種方式來進(jìn)行排序,limit每次不需要跳過任何數(shù)目,直接獲取需要的數(shù)目即可,只需要傳遞上一次的查詢結(jié)果的id即可,這個(gè)方式彌補(bǔ)了上述常規(guī)分頁帶來的問題,并且擁有非常高的性能,但是缺點(diǎn)也顯而易見,不支持跳頁,不支持任意排序,所以這個(gè)方式目前來說非常適合前端app的瀑布流排序。
分片下的實(shí)現(xiàn)
首先分片下需要實(shí)現(xiàn)這個(gè)功能我們需要有id支持分片,并且publish_time按時(shí)間分表,兩者缺一不可。
原理
假設(shè)文章表article我們是以publish_time作為分片字段,假設(shè)按天分表,那么我們會(huì)擁有如下的表:
article_20220101、article_20220102、article_20220103、article_20220104、article_20220105、article_20220106......
雪花id輔助分片
因?yàn)?/span>雪花id 可以反解析出時(shí)間,所以我們對(duì)雪花id的 = , >= , > , <= , < , contains 的操作都是可以進(jìn)行輔助分片進(jìn)行縮小分片范圍,假設(shè)我們的 雪花id 解析出來是2021-01-05 11:11:11,那么針對(duì)這個(gè) 雪花id 的 < 小于操作我們可以等價(jià)于 x < 2021-01-05 11:11:11 ,那么如果我問你這下我們需要查詢的表有哪些,很明顯 [article_20220101、article_20220102、article_20220103、article_20220104、article_20220105],除了20220106外我們都需要查詢。
union all分片模式
如果你使用union all的分片模式,那么通常會(huì)將20220101-20220105的所有的表進(jìn)行union all,然后機(jī)械能過濾,那么優(yōu)點(diǎn)可想而知:簡(jiǎn)單,連接數(shù)消耗僅1個(gè),sql語句支持的多,缺點(diǎn)也顯而易見,優(yōu)化起來后期是個(gè)很大的問題,并且跨庫下的使用有問題。
select * from select * from article_20220101 union all select * from article_20220102 union all select * from article_20220103....) twhere id <last_id order by publish_time desc limit 0 ,20 流式分片,順序查詢 如果你是流式分片模式進(jìn)行聚合,通常我們會(huì)將20220101-20220105的所有的表進(jìn)行并行的分別查詢,然后針對(duì)每個(gè)查詢的結(jié)果集進(jìn)行優(yōu)先級(jí)隊(duì)列的排序后獲取,優(yōu)點(diǎn):語句簡(jiǎn)單便于優(yōu)化、性能可控、支持分庫,缺點(diǎn):實(shí)現(xiàn)復(fù)雜,連接數(shù)消耗多。
select * from article_20220101 where id <last_id order by publish_time desc limit 0 ,20 select * from article_20220102where id <last_id order by publish_time desc limit 0 ,20 select * from article_20220103 where id <last_id order by publish_time desc limit 0 ,20 流式分片下的優(yōu)化 目前 ShardingCore 采用的是流式聚合+union all,當(dāng)且僅當(dāng)用戶手動(dòng)3調(diào)用 UseUnionAllMerge 時(shí)會(huì)將分片sql轉(zhuǎn)成union all 聚合。
針對(duì)上述瀑布流的分頁 ShardingCore 是這么操作的:
確定分片表的順序,也就是因?yàn)榉制侄问?/span>publish_time ,又因?yàn)榕判蜃侄问?/span>publish_time 所以分片表其實(shí)是有順序的,也就是[article_20220105、article_20220104、article_20220103、article_20220102、article_20220101],因?yàn)槲覀兪情_啟n個(gè)并發(fā)線程所以這個(gè)排序可能沒有意義,但是如果我們是僅開啟設(shè)置單個(gè)連接并發(fā)的時(shí)候,程序?qū)F(xiàn)在通過 id<last_id 進(jìn)行表篩選,之后依次從大到小進(jìn)行獲取直到滿足skip+take,也就是0+20=20條數(shù)據(jù)后,進(jìn)行直接拋棄剩余查詢返回結(jié)果,那么本次查詢基本上就是和單表查詢一樣,因?yàn)榛旧献疃嗫鐑蓮埍砘究梢詽M足要求(具體場(chǎng)景不一定)。 說明:假設(shè) last_id 反解析出來的結(jié)果是2022-01-04 05:05:05,那么可以基本上排除 article_20220105 ,判斷并發(fā)連接數(shù)如果是1,那么直接查詢 article_20220104 ,如果不滿足繼續(xù)查詢 article_20220103 ,直到查詢結(jié)果為20條;如果并發(fā)連接數(shù)是2,那么查詢 [article_20220104、article_20220103] ,如果不滿足,繼續(xù)下面兩張表,直到獲取到結(jié)果為20條數(shù)據(jù),所以我們可以很清晰的了解其工作原理并且來優(yōu)化。 說明
通過上述優(yōu)化可以保證流式聚合查詢?cè)陧樞虿樵兿碌母咝阅躉(1) 通過上述優(yōu)化可以保證客戶端分片擁有最小化連接數(shù)控制 設(shè)置合理的主鍵可以有效的解決我們?cè)诖髷?shù)據(jù)分片下的性能優(yōu)化 實(shí)踐 ShardingCore 目前針對(duì)分片查詢進(jìn)行了不斷地優(yōu)化和盡可能的無業(yè)務(wù)代碼入侵來實(shí)現(xiàn)高性能分片查詢聚合。
接下來我將為大家展示一款dotnet下唯一一款全自動(dòng)路由、多字段分片、無代碼入侵、高性能順序查詢的框架 在傳統(tǒng)數(shù)據(jù)庫領(lǐng)域下的分片功能,如果你使用過我相信你一定會(huì)愛上他。
第一步 安裝依賴
# ShardingCore核心框架 版本6.4.2.4+ PM> Install-Package ShardingCore # 數(shù)據(jù)庫驅(qū)動(dòng)這邊選擇的是mysql的社區(qū)驅(qū)動(dòng) efcore6最新版本即可 PM> Install-Package Pomelo.EntityFrameworkCore.MySql 第二步 添加對(duì)象和上下文 有很多朋友問我一定需要使用fluentapi來使用 ShardingCore 嗎?只是個(gè)人喜好,這邊我才用dbset+attribute來實(shí)現(xiàn):
//文章表 Table(nameof(Article)) ]public class Article MaxLength(128) ]Key ]public string Id { get ; set ; }MaxLength(128) ]Required ]public string Title { get ; set ; }MaxLength(256) ]Required ]public string Content { get ; set ; }public DateTime PublishTime { get ; set ; }public class MyDbContext :AbstractShardingDbContext ,IShardingTableDbContext public MyDbContext (DbContextOptions<MyDbContext> options ) : base (options )public IRouteTail RouteTail { get ; set ; }public DbSet<Article> Articles { get ; set ; }第三步 添加文章路由 public class ArticleRoute :AbstractSimpleShardingDayKeyDateTimeVirtualTableRoute <Article >public override void Configure (EntityMetadataTableBuilder<Article> builder )public override bool AutoCreateTableByTime ()return true ;public override DateTime GetBeginTime ()return new DateTime(2022 , 3 , 1 );到目前為止基本上Article已經(jīng)支持了按天分表。
第四步 添加查詢配置,讓框架知道我們是順序分表且定義分表的順序
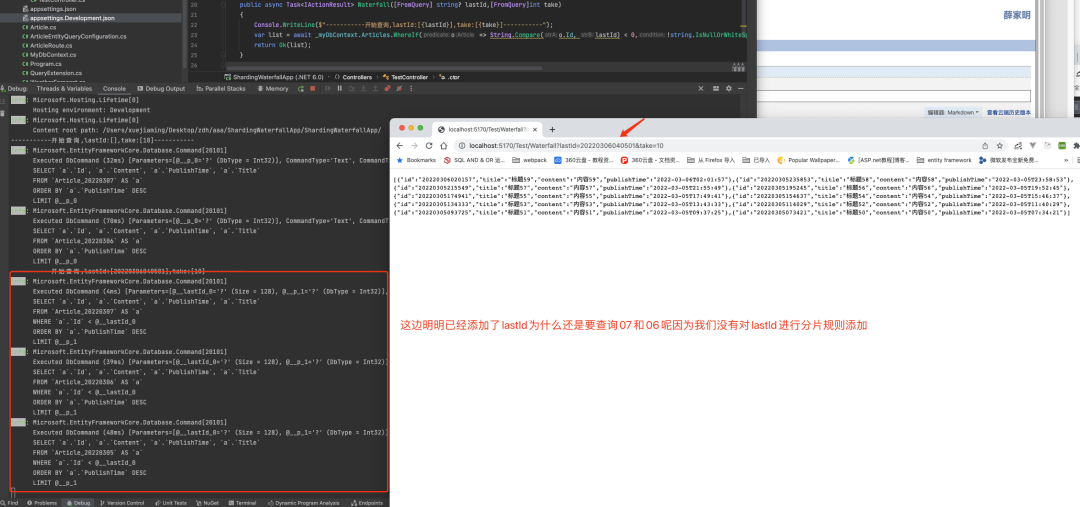
public class TailDayReverseComparer : IComparer <string >public int Compare (string ? x, string ? y//程序默認(rèn)使用的是正序也就是按時(shí)間正序排序我們需要使用倒序所以直接調(diào)用原生的比較器然后乘以負(fù)一即可 return Comparer<string >.Default.Compare(x, y) * -1 ;//當(dāng)前查詢滿足的復(fù)核條件必須是單個(gè)分片對(duì)象的查詢,可以join普通非分片表 public class ArticleEntityQueryConfiguration :IEntityQueryConfiguration <Article >public void Configure (EntityQueryBuilder<Article> builder )//設(shè)置默認(rèn)的框架針對(duì)Article的排序順序,這邊設(shè)置的是倒序 new TailDayReverseComparer());/// /如下設(shè)置和上述是一樣的效果讓框架真對(duì)Article的后綴排序使用倒序//builder.ShardingTailComparer(Comparer<string>.Default, false); //簡(jiǎn)單解釋一下下面這個(gè)配置的意思 //第一個(gè)參數(shù)表名Article的哪個(gè)屬性是順序排序和Tail按天排序是一樣的這邊使用了PublishTime //第二個(gè)參數(shù)表示對(duì)屬性PublishTime asc時(shí)是否和上述配置的ShardingTailComparer一致,true表示一致,很明顯這邊是相反的因?yàn)槟J(rèn)已經(jīng)設(shè)置了tail排序是倒序 //第三個(gè)參數(shù)表示是否是Article屬性才可以,這邊設(shè)置的是名稱一樣也可以,因?yàn)榭紤]到匿名對(duì)象的select false ,SeqOrderMatchEnum.Owner|SeqOrderMatchEnum.Named);//這邊為了演示使用的id是簡(jiǎn)單的時(shí)間格式化所以和時(shí)間的配置一樣 false ,SeqOrderMatchEnum.Owner|SeqOrderMatchEnum.Named);//這邊設(shè)置如果本次查詢默認(rèn)沒有帶上述配置的order的時(shí)候才用何種排序手段 //第一個(gè)參數(shù)表示是否和ShardingTailComparer配置的一樣,目前配置的是倒序,也就是從最近時(shí)間開始查詢,如果是false就是從最早的時(shí)間開始查詢 //后面配置的是熔斷器,也就是復(fù)核熔斷條件的比如FirstOrDefault只需要滿足一個(gè)就可以熔斷 true , CircuitBreakerMethodNameEnum.Enumerator, CircuitBreakerMethodNameEnum.FirstOrDefault);//這邊配置的是當(dāng)使用順序查詢配置的時(shí)候默認(rèn)開啟的連接數(shù)限制是多少,startup一開始可以設(shè)置一個(gè)默認(rèn)是當(dāng)前cpu的線程數(shù),這邊優(yōu)化到只需要一個(gè)線程即可,當(dāng)然如果跨表那么就是串行執(zhí)行 1 , LimitMethodNameEnum.Enumerator, LimitMethodNameEnum.FirstOrDefault);第五步 添加配置到路由 public class ArticleRoute :AbstractSimpleShardingDayKeyDateTimeVirtualTableRoute <Article >//省略..... public override IEntityQueryConfiguration<Article> CreateEntityQueryConfiguration ()return new ArticleEntityQueryConfiguration();第六步 startup配置 var builder = WebApplication.CreateBuilder(args);// Add services to the container. true ;true ;"c1" ;new MySqlServerVersion(new Version())).UseLoggerFactory(efLogger);new MySqlServerVersion(new Version())).UseLoggerFactory(efLogger);"ds0" , "server=127.0.0.1;port=3306;database=ShardingWaterfallDB;userid=root;password=root;" );new MySqlTableEnsureManager<MyDbContext>());var app = builder.Build();using (var scope = app.Services.CreateScope())var myDbContext = scope.ServiceProvider.GetRequiredService<MyDbContext>();if (!myDbContext.Articles.Any())new List<Article>();var beginTime = new DateTime(2022 , 3 , 1 , 1 , 1 ,1 );for (int i = 0 ; i < 70 ; i++)var article = new Article();"yyyyMMddHHmmss" );"標(biāo)題" + i;"內(nèi)容" + i;2 ).AddMinutes(3 ).AddSeconds(4 );第七步 編寫查詢表達(dá)式 public async Task<IActionResult> Waterfall ([FromQuery] string lastId,[FromQuery]int take )$"-----------開始查詢,lastId:[{lastId} ],take:[{take} ]-----------" );var list = await _myDbContext.Articles.WhereIf(o => String.Compare(o.Id, lastId) < 0 ,!string .IsNullOrWhiteSpace(lastId)).Take(take)..OrderByDescending(o => o.PublishTime)ToListAsync();return Ok(list);運(yùn)行程序
因?yàn)?7表是沒有的,所以這次查詢會(huì)查詢07和06表,之后我們進(jìn)行下一次分頁傳入上次id:
因?yàn)闆]有對(duì) Article.Id 進(jìn)行分片路由的規(guī)則編寫,所以沒辦法進(jìn)行對(duì)id的過濾,那么接下來我們配置 Id 的分片規(guī)則。
首先針對(duì) ArticleRoute 進(jìn)行代碼編寫:
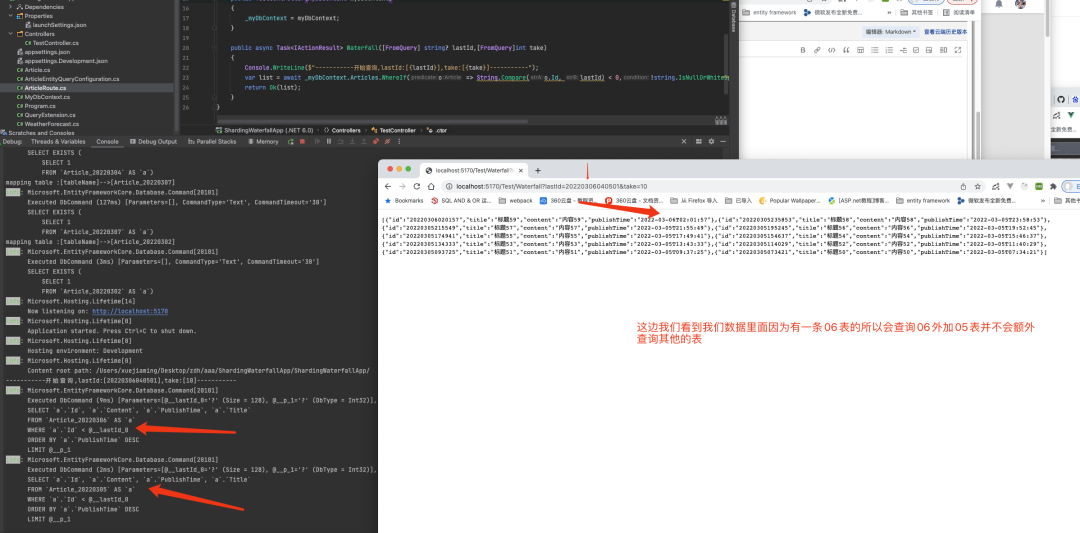
public class ArticleRoute :AbstractSimpleShardingDayKeyDateTimeVirtualTableRoute <Article >public override void Configure (EntityMetadataTableBuilder<Article> builder )public override bool AutoCreateTableByTime ()return true ;public override DateTime GetBeginTime ()return new DateTime(2022 , 3 , 1 );public override IEntityQueryConfiguration<Article> CreateEntityQueryConfiguration ()return new ArticleEntityQueryConfiguration();public override Expression<Func<string , bool >> GetExtraRouteFilter(object shardingKey, ShardingOperatorEnum shardingOperator, string shardingPropertyName)switch (shardingPropertyName)case nameof (Article.Id ): return GetArticleIdRouteFilter (shardingKey, shardingOperator )return base .GetExtraRouteFilter(shardingKey, shardingOperator, shardingPropertyName);/// <summary> /// 文章id的路由/// </summary> /// <param name="shardingKey"></param> /// <param name="shardingOperator"></param> /// <returns></returns> private Expression<Func<string , bool >> GetArticleIdRouteFilter(object shardingKey,//將分表字段轉(zhuǎn)成訂單編號(hào) var id = shardingKey?.ToString() ?? string .Empty;//判斷訂單編號(hào)是否是我們符合的格式 if (!CheckArticleId(id, out var orderTime))//如果格式不一樣就直接返回false那么本次查詢因?yàn)槭莂nd鏈接的所以本次查詢不會(huì)經(jīng)過任何路由,可以有效的防止惡意攻擊 return tail => false ;//當(dāng)前時(shí)間的tail var currentTail = TimeFormatToTail(orderTime);//因?yàn)槭前丛路直硭垣@取下個(gè)月的時(shí)間判斷id是否是在臨界點(diǎn)創(chuàng)建的 //var nextMonthFirstDay = ShardingCoreHelper.GetNextMonthFirstDay(DateTime.Now);//這個(gè)是錯(cuò)誤的 var nextMonthFirstDay = ShardingCoreHelper.GetNextMonthFirstDay(orderTime);if (orderTime.AddSeconds(10 ) > nextMonthFirstDay)var nextTail = TimeFormatToTail(nextMonthFirstDay);return DoArticleIdFilter(shardingOperator, orderTime, currentTail, nextTail);//因?yàn)槭前丛路直硭垣@取這個(gè)月月初的時(shí)間判斷id是否是在臨界點(diǎn)創(chuàng)建的 //if (orderTime.AddSeconds(-10) < ShardingCoreHelper.GetCurrentMonthFirstDay(DateTime.Now))//這個(gè)是錯(cuò)誤的 if (orderTime.AddSeconds(-10 ) < ShardingCoreHelper.GetCurrentMonthFirstDay(orderTime))//上個(gè)月tail var previewTail = TimeFormatToTail(orderTime.AddSeconds(-10 ));return DoArticleIdFilter(shardingOperator, orderTime, previewTail, currentTail);return DoArticleIdFilter(shardingOperator, orderTime, currentTail, currentTail);private Expression<Func<string , bool >> DoArticleIdFilter(ShardingOperatorEnum shardingOperator, DateTime shardingKey, string minTail, string maxTail)switch (shardingOperator)case ShardingOperatorEnum.GreaterThan:case ShardingOperatorEnum.GreaterThanOrEqual:return tail => String.Compare(tail, minTail, StringComparison.Ordinal) >= 0 ;case ShardingOperatorEnum.LessThan:var currentMonth = ShardingCoreHelper.GetCurrentMonthFirstDay(shardingKey);//處于臨界值 o=>o.time < [2021-01-01 00:00:00] 尾巴20210101不應(yīng)該被返回 if (currentMonth == shardingKey)return tail => String.Compare(tail, maxTail, StringComparison.Ordinal) < 0 ;return tail => String.Compare(tail, maxTail, StringComparison.Ordinal) <= 0 ;case ShardingOperatorEnum.LessThanOrEqual:return tail => String.Compare(tail, maxTail, StringComparison.Ordinal) <= 0 ;case ShardingOperatorEnum.Equal:var isSame = minTail == maxTail;if (isSame)return tail => tail == minTail;else return tail => tail == minTail || tail == maxTail;default :return tail => true ;private bool CheckArticleId (string orderNo, out DateTime orderTime//yyyyMMddHHmmss if (orderNo.Length == 14 )if (DateTime.TryParseExact(orderNo, "yyyyMMddHHmmss" , CultureInfo.InvariantCulture,out var parseDateTime))return true ;return false ;完整路由: 針對(duì)Id進(jìn)行多字段分片并且支持大于小于排序。
以上是多字段分片的優(yōu)化, 然后我們繼續(xù)查詢看看結(jié)果:
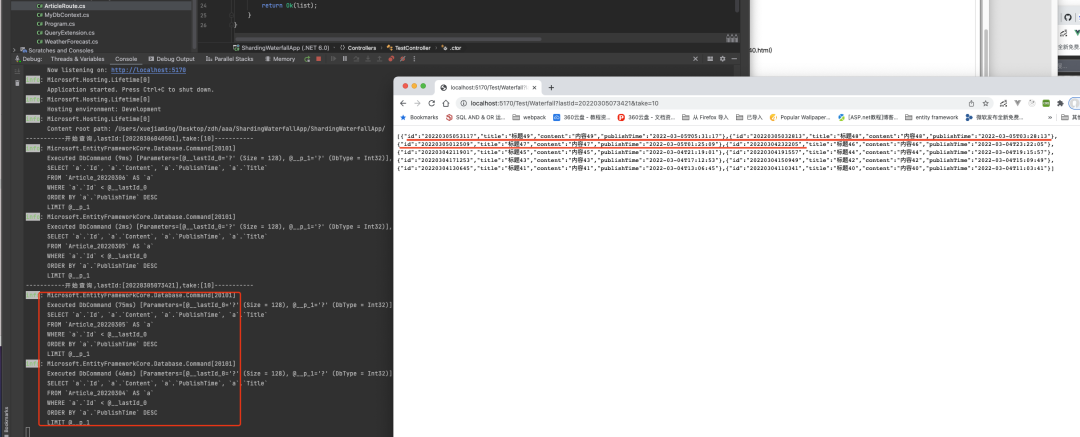
第三頁也是如此
總結(jié) 當(dāng)前框架雖然是一個(gè)很年輕的框架,但是相信對(duì)其在分片領(lǐng)域的性能優(yōu)化應(yīng)該在.net現(xiàn)有的所有框架下找不出第二個(gè),并且框架整個(gè)也支持union all聚合,可以滿足列入group+first的特殊語句的查詢,又有很高的性能,一個(gè)不但是全自動(dòng)分片而且還是高性能框架,擁有非常多的特性性能,目標(biāo)是榨干客戶端分片的最后一點(diǎn)性能。
最后
身位一個(gè)dotnet程序員,我相信在之前我們的分片選擇方案除了 mycat 和 shardingsphere-proxy 外,沒有一個(gè)很好的分片選擇,但是我相信通過 ShardingCore 的原理解析,你不但可以了解到大數(shù)據(jù)下分片的知識(shí)點(diǎn),更加可以參與到其中或者自行實(shí)現(xiàn)一個(gè),我相信只有了解了分片的原理,dotnet才會(huì)有更好的人才和未來,我們不但需要優(yōu)雅的封裝,更需要的是對(duì)原理了解。
我相信未來dotnet的生態(tài)會(huì)慢慢起來配上這近乎完美的語法。
晴ERP是一款針對(duì)中小制造業(yè)的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國內(nèi)大量中小企業(yè)的青睞。")
晴PMS碼頭管理系統(tǒng)主要針對(duì)港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場(chǎng)、車隊(duì)、財(cái)務(wù)費(fèi)用、相關(guān)報(bào)表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點(diǎn),圍繞調(diào)度、堆場(chǎng)作業(yè)而開發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
晴WMS倉儲(chǔ)管理系統(tǒng)提供了貨物產(chǎn)品管理,銷售管理,采購管理,倉儲(chǔ)管理,倉庫管理,保質(zhì)期管理,貨位管理,庫位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號(hào)管理軟件。")
晴免費(fèi)OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時(shí)間、不限用戶的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")


 400 186 1886
400 186 1886
晴公司官網(wǎng)")

