[點(diǎn)晴永久免費(fèi)OA]蘋果 iCloud 發(fā)布這么多年,如何實(shí)現(xiàn)存儲(chǔ)數(shù)十億個(gè)數(shù)據(jù)庫還不卡頓的?
作者 | Leonardo Creed 翻譯 | 蘇宓 出品 | CSDN(ID:CSDNnews) 在眾多科技巨頭中,相比 Google、微軟、Meta 等公司,蘋果無論是在 iOS 系統(tǒng),還是很多新興技術(shù)研發(fā)方面,都保持著一定的神秘感,鮮少有人知道蘋果公司的基礎(chǔ)設(shè)施是如何構(gòu)建出來的? 近日,軟件工程師 Leonardo Creed 在查閱了大量的論文以及整理了多個(gè)技術(shù)細(xì)節(jié)之后,向眾人分享了蘋果是如何構(gòu)建在線同步存儲(chǔ)服務(wù)和云端計(jì)算服務(wù) iCloud 的,也揭曉了它如何實(shí)現(xiàn)存儲(chǔ)數(shù)十億個(gè)數(shù)據(jù)庫的。通過本篇文章,也希望給相關(guān)的從業(yè)者帶來更多的思考與幫助。 以下為譯文:
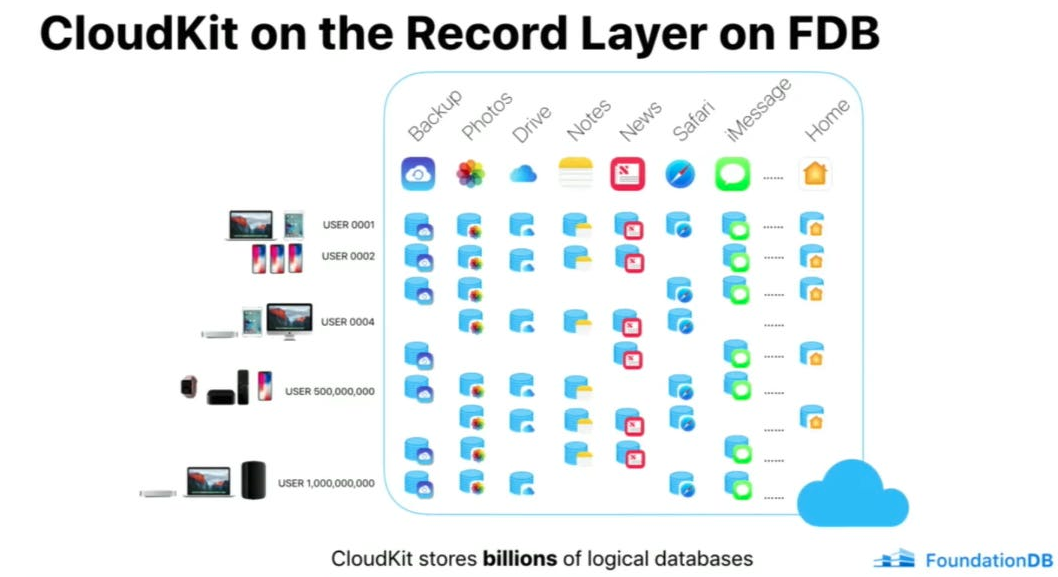
永恒的現(xiàn)實(shí)世界課程 蘋果在 iCloud 和 CloudKit(他們的云計(jì)算后端服務(wù))中使用了 FoundationDB 和 Cassandra。是的,標(biāo)題沒有錯(cuò): 蘋果確實(shí)在其極端多租戶架構(gòu)中存儲(chǔ)了數(shù)十億個(gè)數(shù)據(jù)庫。 在正式解析其架構(gòu)之前,我想分享自己發(fā)現(xiàn)的一些亮點(diǎn),本篇文章以及蘋果公司的許多經(jīng)驗(yàn)與我之前寫過的“Meta 無服務(wù)器平臺(tái)架構(gòu)”的在某些技術(shù)點(diǎn)上有些相似(https://read.engineerscodex.com/p/meta-xfaas-serverless-functions-explained)。
Cassandra 數(shù)據(jù)庫 Cassandra 是一種開源的 NoSQL 數(shù)據(jù)庫管理系統(tǒng)。它最初由 Facebook 開發(fā),用于支持 Facebook 收件箱搜索功能。有趣的是,在 2021 年,Meta 自己開始用 ZippyDB 取代了大部分 Cassandra 的使用。 iCloud 部分采用了 Cassandra。據(jù)一家位于加利福尼亞州圣克拉拉的實(shí)時(shí)人工智能數(shù)據(jù)公司 DataStax(旗下主要產(chǎn)品基于 Apache Cassandra)稱,蘋果運(yùn)行著世界上最大的 Cassandra 部署之一。 在他們發(fā)布的報(bào)告中,透露了蘋果在 Cassandra 方面有:
對(duì)此,此前也有不少蘋果前員工透露,iCloud 服務(wù)中 Cassandra 所管理的數(shù)據(jù)量高達(dá)數(shù)億字節(jié)。每臺(tái)服務(wù)器有多個(gè) Cassandra 節(jié)點(diǎn),這確保了 iCloud 數(shù)據(jù)的可用性接近 100%。 至此,蘋果公司內(nèi)部團(tuán)隊(duì)仍在積極改進(jìn) Cassandra。上個(gè)月,蘋果公司的 Cassandra 存儲(chǔ)工程經(jīng)理 Scott Andreas 在一次會(huì)議上就 Cassandra 的未來發(fā)表了演講。在蘋果公司的招聘頁面上,他們也在招聘分布式系統(tǒng)工程師時(shí)通常會(huì)提到 Cassandra。 然而,CloudKit + Cassandra 的解決方案在實(shí)際應(yīng)用中遇到了兩個(gè)可擴(kuò)展性限制,因此蘋果工程團(tuán)隊(duì)后來引入并采用了 FoundationDB:
FoundationDB 和記錄層解決了這兩個(gè)問題。
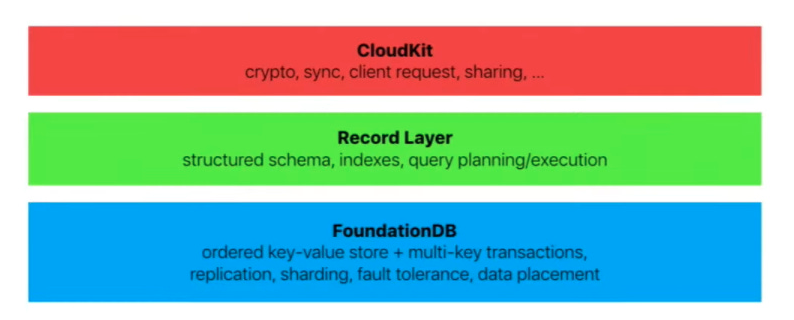
FoundationDB 數(shù)據(jù)庫 蘋果公司對(duì) FoundationDB 的態(tài)度更為公開。他們?cè)?2015 年收購了數(shù)據(jù)庫公司 FoundationDB,并在此后發(fā)表了多篇論文,詳細(xì)介紹了他們對(duì) FoundationDB 的使用。 FoundationDB 是一種開源、分布式、事務(wù)性鍵值存儲(chǔ)。它專為處理大量數(shù)據(jù)而設(shè)計(jì),并且非常適合讀/寫工作負(fù)載和寫入密集型工作負(fù)載。它還符合 ACID 標(biāo)準(zhǔn)。 Apple 在 CloudKit(Apple 的云計(jì)算后端服務(wù))中廣泛使用 FoundationDB 記錄層。
在 FoundationDB 記錄層的 GitHub 頁面上,該團(tuán)隊(duì)詳細(xì)介紹道: 記錄層(Record Layer)是一個(gè) Java API,它在 FoundationDB 的基礎(chǔ)上提供了一個(gè)面向記錄的存儲(chǔ),(非常)大致相當(dāng)于一個(gè)簡(jiǎn)單的關(guān)系數(shù)據(jù)庫,具有以下特點(diǎn):
在 FoundationDB 記錄層論文中,他們寫道:“[FoundationDB 記錄層用于]為服務(wù)于數(shù)億用戶的應(yīng)用程序提供強(qiáng)大的抽象。CloudKit 使用記錄層來托管數(shù)十億個(gè)獨(dú)立數(shù)據(jù)庫,其中許多數(shù)據(jù)庫具有共同的模式。”
為什么使用 FoundationDB 記錄層? FoundationDB、Record Layer 和 CloudKit 的結(jié)構(gòu)如下所示:
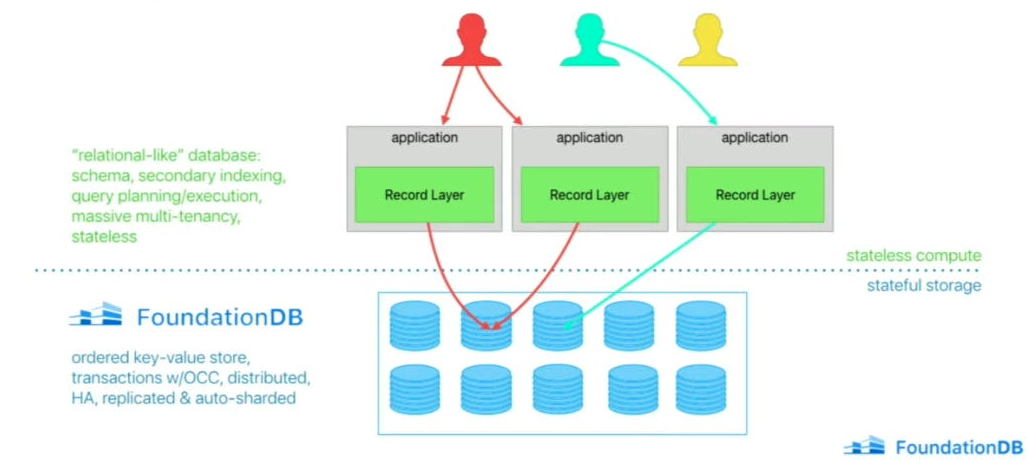
記錄層允許蘋果大規(guī)模支持多租戶。 事實(shí)上,這樣說有點(diǎn)言過其實(shí)。 記錄層用于極端多租戶,其中每個(gè)應(yīng)用程序的每個(gè)用戶都能獲得獨(dú)立的記錄存儲(chǔ)。這意味著記錄層可托管數(shù)十億個(gè)獨(dú)立數(shù)據(jù)庫,共享數(shù)千個(gè)模式。 這樣更好!而且更令人印象深刻。
記錄層之所以能夠處理如此大規(guī)模的多租戶問題,主要得益于兩個(gè)基本的架構(gòu)決策: 1. 該層以無狀態(tài)方式運(yùn)行,只需添加更多無狀態(tài)實(shí)例,即可輕松擴(kuò)展計(jì)算資源。
2. 該層使用記錄存儲(chǔ)抽象來有效管理資源分配和可擴(kuò)展性。這種抽象代表了邏輯數(shù)據(jù)庫的全部?jī)?nèi)容,包括序列化數(shù)據(jù)、索引和運(yùn)行狀態(tài)。
至此,我們可以粗略地了解一下蘋果公司是如何構(gòu)建 iCloud 的。
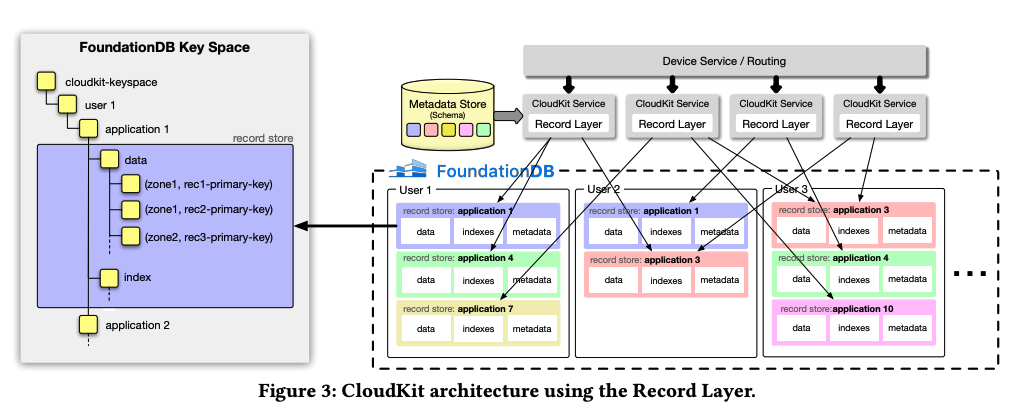
CloudKit 如何使用 FoundationDB 和記錄層? 在 CloudKit 中,應(yīng)用程序由“邏輯容器”(logical container)表示,該容器遵循定義的模式。該架構(gòu)概述了實(shí)現(xiàn)高效數(shù)據(jù)檢索和查詢所需的記錄類型、字段和索引。應(yīng)用程序?qū)⑵鋽?shù)據(jù)組織到 CloudKit 中的“區(qū)域”中,這樣就可以對(duì)記錄進(jìn)行邏輯分組,以便有選擇地與客戶端設(shè)備同步。
對(duì)于每個(gè)用戶,CloudKit 都會(huì)在 FoundationDB 中指定一個(gè)唯一的子空間。在這個(gè)子空間中,它會(huì)為用戶與之交互的每個(gè)應(yīng)用程序創(chuàng)建一個(gè)記錄存儲(chǔ)空間。從本質(zhì)上講,CloudKit 管理著大量邏輯數(shù)據(jù)庫(用戶數(shù)量乘以應(yīng)用程序數(shù)量),每個(gè)數(shù)據(jù)庫都包含自己的記錄、索引和元數(shù)據(jù)集,總計(jì)數(shù)十億個(gè)數(shù)據(jù)庫。 當(dāng) CloudKit 收到來自客戶端設(shè)備的請(qǐng)求時(shí),它會(huì)通過負(fù)載均衡將該請(qǐng)求定向到可用的 CloudKit 服務(wù)進(jìn)程。然后,該進(jìn)程與特定的記錄層記錄存儲(chǔ)進(jìn)行交互,以滿足請(qǐng)求。 CloudKit 會(huì)將已定義的應(yīng)用程序模式轉(zhuǎn)換為記錄層中的元數(shù)據(jù)定義,并將其存儲(chǔ)在單獨(dú)的元數(shù)據(jù)存儲(chǔ)區(qū)中。該元數(shù)據(jù)由 CloudKit 特定的系統(tǒng)字段進(jìn)行擴(kuò)充,這些字段用于跟蹤記錄的創(chuàng)建、修改時(shí)間和記錄存儲(chǔ)的區(qū)域。區(qū)域名稱以主鍵為前綴,以便能夠高效訪問每個(gè)區(qū)域內(nèi)的記錄。除了用戶定義的索引外,CloudKit 還管理用于內(nèi)部目的的“系統(tǒng)索引”,例如通過保留按類型跟蹤記錄大小的索引來管理存儲(chǔ)配額。 FoundationDB 和記錄層共同為蘋果公司解決了 4 個(gè)關(guān)鍵問題,這是單獨(dú)使用 Cassandra 或單獨(dú)使用 FoundationDB 都無法解決的。
問題一:個(gè)性化全文搜索 FoundationDB 幫助用戶解決個(gè)性化全文搜索問題,以便快速訪問數(shù)據(jù)。 蘋果的系統(tǒng)利用 FoundationDB 的排序鍵順序,可以快速搜索文本開頭(前綴匹配),也可以進(jìn)行更復(fù)雜的搜索(如查找相鄰或按特定順序排列的單詞——近似搜索和短語搜索),而無需額外的開銷。 在傳統(tǒng)的搜索系統(tǒng)中,你通常需要在后臺(tái)運(yùn)行額外的進(jìn)程來保持搜索索引的更新,但蘋果的系統(tǒng)可以實(shí)時(shí)完成所有工作,這意味著一旦數(shù)據(jù)發(fā)生變化,搜索索引就會(huì)立即更新,無需額外的步驟。
問題二:高并發(fā)情況 有了 FoundationDB,CloudKit 可以流暢地處理同時(shí)發(fā)生的許多更新。 以前,在使用 Cassandra 時(shí),CloudKit 需要依靠一個(gè)特殊的索引來跟蹤每個(gè)區(qū)域的變化,從而實(shí)現(xiàn)跨設(shè)備的數(shù)據(jù)同步。當(dāng)設(shè)備需要更新其數(shù)據(jù)時(shí),它會(huì)檢查該索引以查看新內(nèi)容。但這種系統(tǒng)有一個(gè)缺點(diǎn):當(dāng)多個(gè)更新同時(shí)發(fā)生時(shí),可能會(huì)造成沖突。 但在 FoundationDB 中,CloudKit 使用了一種特殊的索引,它能準(zhǔn)確記錄每次更改的順序,而不會(huì)造成沖突。具體做法是為每次更改分配一個(gè)唯一的“版本”,當(dāng) CloudKit 需要同步時(shí),它會(huì)查看這些版本,以確定設(shè)備錯(cuò)過了哪些更新。 然而,當(dāng) CloudKit 需要在不同的存儲(chǔ)集群之間移動(dòng)數(shù)據(jù)時(shí)(也許是為了更均勻地分配負(fù)載),事情就變得棘手了,因?yàn)槊總€(gè)集群都有自己的版本號(hào),而這些版本號(hào)并不一致。 為了解決這個(gè)問題,CloudKit 為每個(gè)用戶的數(shù)據(jù)提供了一個(gè)“移動(dòng)計(jì)數(shù)”(稱為 “化身”),每次將其數(shù)據(jù)傳輸?shù)叫碌募簳r(shí),該計(jì)數(shù)都會(huì)增加。每次記錄更新都包含用戶當(dāng)前的“化身”編號(hào),確保即使在移動(dòng)后,CloudKit 仍能通過查看化身編號(hào)和版本編號(hào)來確定正確的更新順序。 在轉(zhuǎn)到新系統(tǒng)時(shí),CloudKit 面臨著處理沒有版本號(hào)的舊數(shù)據(jù)的挑戰(zhàn)。蘋果工程團(tuán)隊(duì)巧妙地克服了這一難題,他們通過使用一個(gè)特殊的功能,在新系統(tǒng)之前使用以前的系統(tǒng)對(duì)舊更新進(jìn)行排序。這意味著無需對(duì)應(yīng)用程序進(jìn)行復(fù)雜的更改,也不會(huì)留下過時(shí)的代碼。該函數(shù)考慮了版本、版本號(hào)和舊的更新計(jì)數(shù)器值,以保持記錄的正確順序。
問題三:高延遲查詢 FoundationDB 是為高并發(fā)而不是低延遲而設(shè)計(jì)的。這意味著它可以同時(shí)處理大量任務(wù),而不是專注于單個(gè)任務(wù)的速度。
為了充分利用這種設(shè)計(jì),記錄層的許多工作都是“異步”進(jìn)行的——它將將來要完成的任務(wù)排隊(duì),允許同時(shí)完成其他工作。這種方法有助于掩蓋這些任務(wù)中可能出現(xiàn)的任何延遲。 不過,F(xiàn)oundationDB 用來與其數(shù)據(jù)庫通信的工具,是設(shè)計(jì)為使用單線程聯(lián)網(wǎng),一次只做一件事。在早期版本中,這種設(shè)置造成了系統(tǒng)中的交通堵塞,因?yàn)樗械氖虑槎荚诘却喌竭@個(gè)網(wǎng)絡(luò)線程。記錄層一直使用這種單線程方法,這導(dǎo)致了瓶頸。 為了改善這一問題,蘋果減少了網(wǎng)絡(luò)線程的工作量。現(xiàn)在,復(fù)雜的任務(wù)看起來速度更快了,因?yàn)橄到y(tǒng)同時(shí)在幾個(gè)方面與數(shù)據(jù)庫合作,而不是形成一個(gè)隊(duì)列。這樣,延遲或表面上的緩慢就被掩蓋了,因?yàn)橄到y(tǒng)不會(huì)等一個(gè)任務(wù)完成后再開始另一個(gè)任務(wù)。
問題四:事務(wù)沖突 在 FoundationDB 中,如果一個(gè)事務(wù)正在讀取某些鍵,而另一個(gè)事務(wù)同時(shí)修改了這些鍵,就會(huì)導(dǎo)致“事務(wù)沖突”。FoundationDB 通過提供對(duì)控制讀取或?qū)懭霑r(shí)可能導(dǎo)致沖突的鍵集,來精確管理這些沖突。 一種避免不必要沖突的常用方法是,在鍵的范圍內(nèi)執(zhí)行一種不會(huì)導(dǎo)致沖突的特殊讀取,稱為“快照”讀取。如果這種讀取發(fā)現(xiàn)了重要的鍵,事務(wù)將只標(biāo)記那些可能發(fā)生沖突的特定鍵,而不是整個(gè)范圍。這樣可以確保事務(wù)只受對(duì)其結(jié)果有實(shí)際影響的變化的影響。 記錄層使用這種策略來有效管理被稱之為跳過列表的數(shù)據(jù)結(jié)構(gòu),這是其排序索引系統(tǒng)的一部分。不過,手動(dòng)設(shè)置這些沖突范圍可能比較麻煩,而且可能導(dǎo)致難以識(shí)別的錯(cuò)誤,尤其是當(dāng)它們與應(yīng)用程序的主要邏輯混合在一起時(shí)。 因此,建議在 FoundationDB 基礎(chǔ)上構(gòu)建的系統(tǒng)創(chuàng)建更高級(jí)別的工具(如自定義索引)來處理這些模式。這種方法有助于避免將放寬沖突規(guī)則的責(zé)任留給每個(gè)客戶端應(yīng)用程序,從而導(dǎo)致錯(cuò)誤和不一致。
對(duì)于 Leonardo Creed 的分享,不少開發(fā)者對(duì)此也有了更深度的思考: 亞馬遜就是這么做 Aurora 的。將所有狀態(tài)轉(zhuǎn)移到對(duì)象存儲(chǔ)層,而對(duì)象存儲(chǔ)層也是處理過程的末端(經(jīng)過 lb、前端、后端、數(shù)據(jù)庫,最后到磁盤)。無狀態(tài)基本上就是把所有東西都移到后端。 我敢肯定,Google 也在做同樣的事情/已經(jīng)開始做了。同時(shí),這也使其“易于”橫向擴(kuò)展:只要你能在對(duì)象層面上進(jìn)行抽象,你就可以擴(kuò)展你的底層基礎(chǔ)架構(gòu),以便只處理“對(duì)象”。 也有一位蘋果前員工評(píng)論道: 遺憾的是,我在蘋果公司工作時(shí)從未參與過這方面的工作(不過我參加過這方面的面試!),但幾年前聽到的這件事讓我意識(shí)到了一些本該顯而易見的事情:數(shù)據(jù)庫和文件系統(tǒng)之間其實(shí)并沒有什么區(qū)別。 從根本上說,它們做的是同一件事,只是針對(duì)特定問題集進(jìn)行了優(yōu)化。數(shù)據(jù)庫適用于有適當(dāng)索引的數(shù)據(jù),而文件系統(tǒng)則適用于更為隨意的數(shù)據(jù)。 如果你是一個(gè)足夠聰明的工程師,你可以用數(shù)據(jù)庫來定義文件系統(tǒng),iCloud 就是一個(gè)很好的例子。就我個(gè)人而言,我利用這些知識(shí)使用 Cassandra 為 HLS 流存儲(chǔ)視頻數(shù)據(jù)塊。這讓我獲得了很多 Cassandra 的分布式優(yōu)勢(shì),但代價(jià)是不得不重新發(fā)明一些文件系統(tǒng)的東西。 參考鏈接: https://read.engineerscodex.com/p/how-apple-built-icloud-to-store-billions https://news.ycombinator.com/item?id=39028672 ———————————————— 版權(quán)聲明:本文為CSDN博主「CSDN資訊」的原創(chuàng)文章,遵循CC 4.0 BY-SA版權(quán)協(xié)議,轉(zhuǎn)載請(qǐng)附上原文出處鏈接及本聲明。 原文鏈接:https://blog.csdn.net/csdnnews/article/details/135687614 該文章在 2024/1/23 17:03:26 編輯過 |
關(guān)鍵字查詢
相關(guān)文章
正在查詢... 晴ERP是一款針對(duì)中小制造業(yè)的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國內(nèi)大量中小企業(yè)的青睞。")
晴PMS碼頭管理系統(tǒng)主要針對(duì)港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場(chǎng)、車隊(duì)、財(cái)務(wù)費(fèi)用、相關(guān)報(bào)表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點(diǎn),圍繞調(diào)度、堆場(chǎng)作業(yè)而開發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
晴WMS倉儲(chǔ)管理系統(tǒng)提供了貨物產(chǎn)品管理,銷售管理,采購管理,倉儲(chǔ)管理,倉庫管理,保質(zhì)期管理,貨位管理,庫位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號(hào)管理軟件。")
晴免費(fèi)OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時(shí)間、不限用戶的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")
|


 400 186 1886
400 186 1886
晴公司官網(wǎng)")