6種SQL數(shù)據(jù)去重技巧大揭秘!
當(dāng)前位置:點(diǎn)晴教程→知識(shí)管理交流
→『 技術(shù)文檔交流 』
當(dāng)面試官詢(xún)問(wèn)你如何在SQL中去除重復(fù)的記錄,只保留獨(dú)一無(wú)二的值時(shí),你是否只能想到使用DISTINCT關(guān)鍵字呢?別擔(dān)心,今天,我將分享給你6種去重方法,讓你在面試中脫穎而出。畢竟,只有一個(gè)DISTINCT也太單調(diào)了嘛! 首先,我們創(chuàng)建2個(gè)表并插入些數(shù)據(jù),用于演示去重方法。
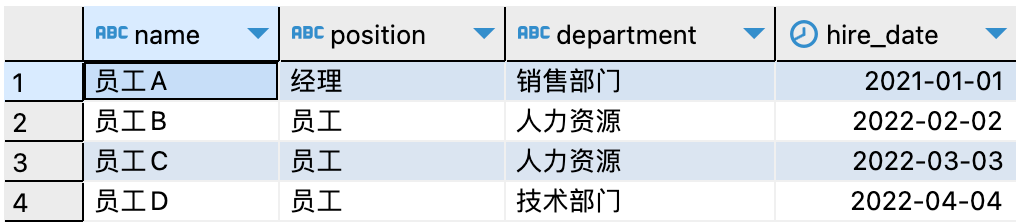
其中,employees表查詢(xún)結(jié)果如下:
salaries表查詢(xún)結(jié)果如下:
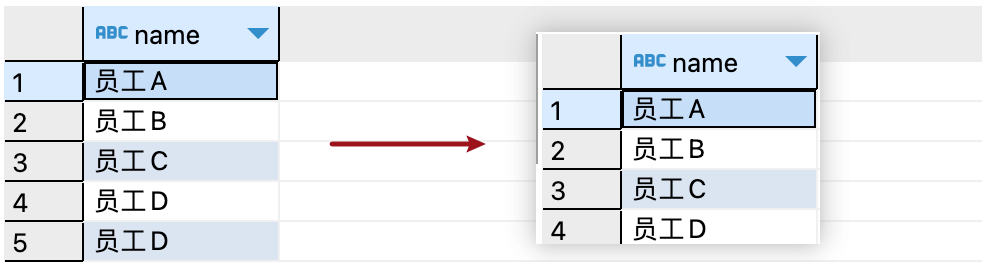
01. 使用DISTINCT關(guān)鍵字去重 DISTINCT關(guān)鍵字是SQL中常用的去重工具。當(dāng)我們使用它時(shí),后面需明確指定要去重的字段。這樣,它將對(duì)指定的字段進(jìn)行去重操作,并返回唯一的值。 1. 對(duì)單列數(shù)據(jù)去重 如果我們想要獲取"employees"表中不重復(fù)的name字段,可以使用以下SQL語(yǔ)句:
查詢(xún)結(jié)果如下:
對(duì)單列使用distinct去除重復(fù)值時(shí),會(huì)過(guò)濾掉多余重復(fù)相同的值,只返回唯一的值。
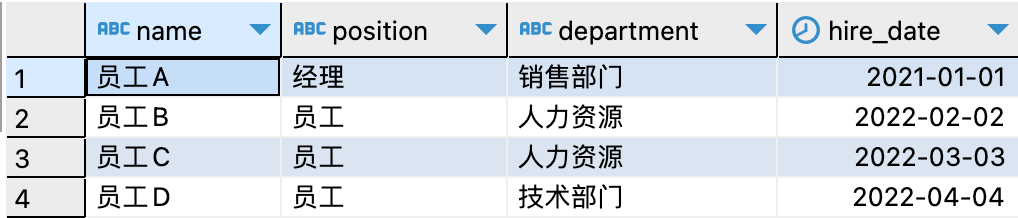
2. 對(duì)多列數(shù)據(jù)去重 如果需要對(duì)多列數(shù)據(jù)進(jìn)行去重處理,只需在DISTINCT關(guān)鍵字后依次列出需要去重的字段名,并用英文逗號(hào)隔開(kāi)即可。 例如,我們想要對(duì)"employees"表中name、position、department和hire_date字段去重,可以使用以下SQL語(yǔ)句。
查詢(xún)結(jié)果如下:
可以看到department的值是有重復(fù)的,這是因?yàn)镈ISTINCT其實(shí)是對(duì)后面所有列名的組合進(jìn)行去重。也就是name+position+department+hire_date組合成的一行在整張表中都不重復(fù)的記錄;在這里,因?yàn)?strong style="margin: 0px; padding: 0px; outline: 0px; max-width: 100%; box-sizing: border-box !important; overflow-wrap: break-word !important;">name+position+department+hire_date有2個(gè)相同的數(shù)據(jù),則過(guò)濾了一行。 使用DISTINCT關(guān)鍵字進(jìn)行去重是相對(duì)簡(jiǎn)單的。然而,需要注意的是,DISTINCT關(guān)鍵字僅對(duì)指定的字段進(jìn)行去重,如果需要返回其他字段的信息,這種方法可能會(huì)受到限制。 02. 使用GROUP BY子句去重 GROUP BY關(guān)鍵字是另一種常用的去重方法。它可以將相同的值分組,并只返回每組中的一個(gè)值。同時(shí),它還可以返回其他字段信息,實(shí)現(xiàn)去重的同時(shí)提供更多相關(guān)信息。以下是GROUP BY子句的2種常見(jiàn)去重方法: 1. 對(duì)單列數(shù)據(jù)去重 如果我們想要獲取"employees"表中不重復(fù)的name字段,可以使用以下SQL語(yǔ)句:
查詢(xún)結(jié)果如下:
2. 對(duì)多列數(shù)據(jù)去重 倘若我們想要對(duì)"employees"表中name、position、department和hire_date字段去重,我們嘗試使用GROUP BY子句如下:
在SQL 查詢(xún)時(shí),若是啟用了only_full_group_by 規(guī)則,那么,當(dāng)在 GROUP BY 子句中沒(méi)有列出的字段,又在 SELECT 中出現(xiàn)且沒(méi)有使用聚合函數(shù),就會(huì)導(dǎo)致錯(cuò)誤。簡(jiǎn)單來(lái)說(shuō),SELECT 中的字段要么是 GROUP BY 里的,要么就得用聚合函數(shù)處理,否則查詢(xún)會(huì)失敗。 正確語(yǔ)法如下:
查詢(xún)結(jié)果如下:
3. 結(jié)合聚合函數(shù) 如果我們不僅想對(duì)name字段去重,還想獲取每個(gè)員工的最早出生日期,可以這樣寫(xiě):
查詢(xún)結(jié)果如下:
這個(gè)查詢(xún)返回了name字段的唯一值和與之相關(guān)的birth_date字段的最小值。 也就是說(shuō),我們可以使用GROUP BY返回分組字段或其他字段的聚合信息。 03. 使用NOT EXISTS子查詢(xún)?nèi)ブ?/span> NOT EXISTS是一種邏輯運(yùn)算符,用于判斷一個(gè)子查詢(xún)是否返回結(jié)果。如果子查詢(xún)沒(méi)有返回結(jié)果,則返回TRUE;否則返回FALSE。我們可以利用這個(gè)特性來(lái)去除重復(fù)的記錄。 倘若我們想要獲取"employees"表中重復(fù)名字中第一個(gè)出現(xiàn)的員工,可以使用以下SQL語(yǔ)句:
這個(gè)查詢(xún)將返回employees表中emp_id, name和birth_date列,且排除其他員工名與當(dāng)前員工相同,且他的emp_id小于當(dāng)前員工的emp_id。換句話說(shuō),將返回重復(fù)名字中emp_id最小的那個(gè)員工信息。 查詢(xún)結(jié)果如下:
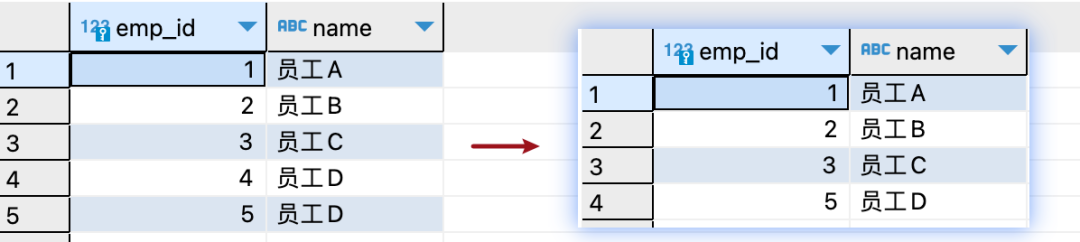
04. 使用LAG和LEAD函數(shù)去重 在SQL中,LAG和LEAD函數(shù)允許我們?cè)L問(wèn)結(jié)果集中的前一行和后一行的數(shù)據(jù),這在處理時(shí)間序列數(shù)據(jù)或比較當(dāng)前行與相鄰行數(shù)據(jù)時(shí)非常有用。我們可以巧妙地使用這些函數(shù)與其他SQL功能(如:GROUP BY、HAVING和DISTINCT) 結(jié)合起來(lái)實(shí)現(xiàn)去重的目的。 如果我們想要獲取"employees"表中不重復(fù)的emp_id、name字段,可以使用以下SQL語(yǔ)句:
這個(gè)語(yǔ)句是從employees表中選擇唯一的emp_id和name。內(nèi)部查詢(xún)使用LAG函數(shù)來(lái)獲取每個(gè)emp_id的前一個(gè)name(按照emp_id排序),如果前一個(gè)name不存在,則默認(rèn)為''(空字符串)。最后,在外部查詢(xún)中,我們篩選出prev_name為NULL或者prev_name與當(dāng)前name不相等的記錄。這種方式可以找出名字在員工列表中發(fā)生變化的員工的emp_id和name。 查詢(xún)結(jié)果如下:
若將上述SQL語(yǔ)句中的LAG函數(shù)替換為L(zhǎng)EAD函數(shù)后,我們可以訪問(wèn)結(jié)果集中的后一行數(shù)據(jù),而不是前一行數(shù)據(jù)。因此,執(zhí)行結(jié)果將與原始SQL語(yǔ)句相反。
05. 使用IN去重 使用"IN"操作可以找到一組數(shù)據(jù)中不重復(fù)的特征,然后基于這些特征來(lái)獲取數(shù)據(jù)。這樣,我們能夠更精確地篩選出具有特定屬性的數(shù)據(jù),確保數(shù)據(jù)的唯一性。 倘若我們想要獲取"employees"表中具有相同名字的最大"emp_id"的員工信息,可以使用以下SQL語(yǔ)句:
查詢(xún)結(jié)果如下:
可以看到返回了emp_id值為5的員工信息,而不是emp_id為4的員工信息。 然而,這種方法的可行性取決于表中是否存在一個(gè)唯一標(biāo)識(shí)每條記錄的字段,也就是,一個(gè)數(shù)據(jù)不重復(fù)的字段,例如employees表中的emp_id字段。若表中不存在此類(lèi)字段,該方法則無(wú)法適用。 06. 使用UNION去重 UNION 是 SQL 中用于合并兩個(gè)或多個(gè) SELECT 語(yǔ)句的結(jié)果集的操作符。當(dāng)使用 UNION 時(shí),結(jié)果集會(huì)自動(dòng)去重,即重復(fù)的行只會(huì)出現(xiàn)一次。這與INNER JOIN類(lèi)似,都是求并集,但INNER JOIN是根據(jù)兩個(gè)或多個(gè)表的共同列來(lái)合并數(shù)據(jù),只返回匹配的行。 倘如,我們想要獲取"employees"表中不重復(fù)的name字段,可以使用以下SQL語(yǔ)句:
這條語(yǔ)句會(huì)從 "employees" 表和 "salaries" 表中選取 "name" 字段,并通過(guò) UNION 操作符合并結(jié)果集,確保結(jié)果中的 "name" 值是唯一的。 查詢(xún)結(jié)果如下:
🌟 使用時(shí)需注意:
除了以上提到的方法,還有許多其他的去重技巧,比如:ROW_NUMBER()窗口函數(shù)、EXCEPT運(yùn)算符、SET運(yùn)算符,以及INNER JOIN結(jié)合GROUP BY等。
關(guān)于SQL中去重的方法,就分享到這了~
希望這個(gè)系列能幫助大家更深入地理解和運(yùn)用數(shù)據(jù)庫(kù)。 該文章在 2024/1/31 12:35:07 編輯過(guò) |
關(guān)鍵字查詢(xún)
相關(guān)文章
正在查詢(xún)... 晴ERP是一款針對(duì)中小制造業(yè)的專(zhuān)業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國(guó)內(nèi)大量中小企業(yè)的青睞。")
晴PMS碼頭管理系統(tǒng)主要針對(duì)港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場(chǎng)、車(chē)隊(duì)、財(cái)務(wù)費(fèi)用、相關(guān)報(bào)表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點(diǎn),圍繞調(diào)度、堆場(chǎng)作業(yè)而開(kāi)發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類(lèi)企業(yè)的高效ERP管理信息系統(tǒng)。")
晴WMS倉(cāng)儲(chǔ)管理系統(tǒng)提供了貨物產(chǎn)品管理,銷(xiāo)售管理,采購(gòu)管理,倉(cāng)儲(chǔ)管理,倉(cāng)庫(kù)管理,保質(zhì)期管理,貨位管理,庫(kù)位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號(hào)管理軟件。")
晴免費(fèi)OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時(shí)間、不限用戶(hù)的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")
|


 400 186 1886
400 186 1886
晴公司官網(wǎng)")