為什么開源數據庫PostgreSQL是未來數據的基石?
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
如今,軟件開發中最大的趨勢之一,是 PostgreSQL 正在成為事實上的數據庫標準。已經有一些博客闡述了如何做到 萬物皆用 PostgreSQL,但還沒有多少文章能解釋這一現象背后的原因。(更重要的是,為什么這件事很重要) —— 所以我寫下了這篇文章。
目錄01 PostgreSQL 正成為數據庫事實標準02 萬物都開始計算機化03 PostgreSQL 王者歸來04 解放雙手,構建未來,擁抱 PostgreSQL PostgreSQL 正成為數據庫事實標準在過去幾個月,“一切皆用 PostgreSQL 解決” 已經成為開發者們的戰斗口號:
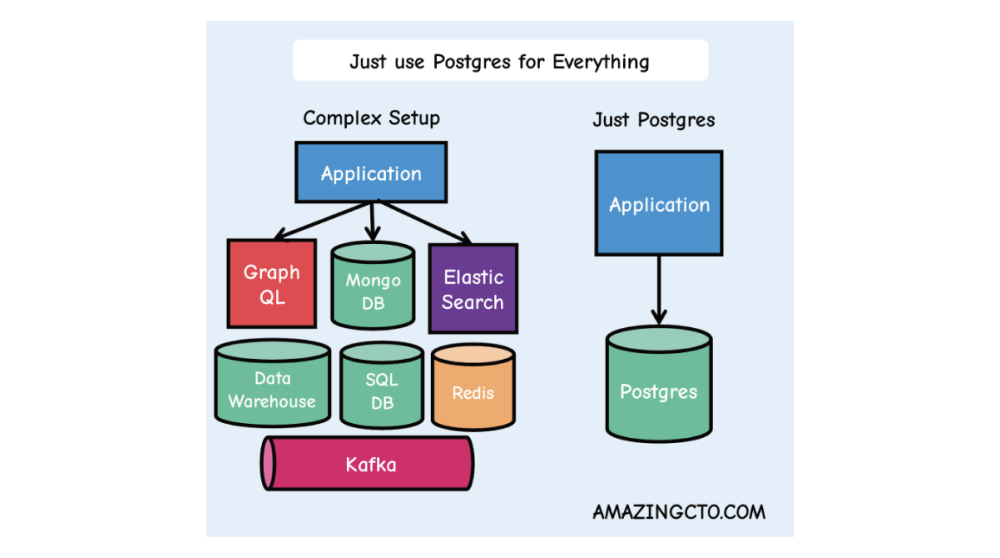
憑借其堅如磐石的基礎,加上其原生功能與擴展插件帶來的強大功能集,開發者現在可以單憑 PostgreSQL 解決所有問題,用簡潔明了的方式,取代復雜且脆弱的數據架構。
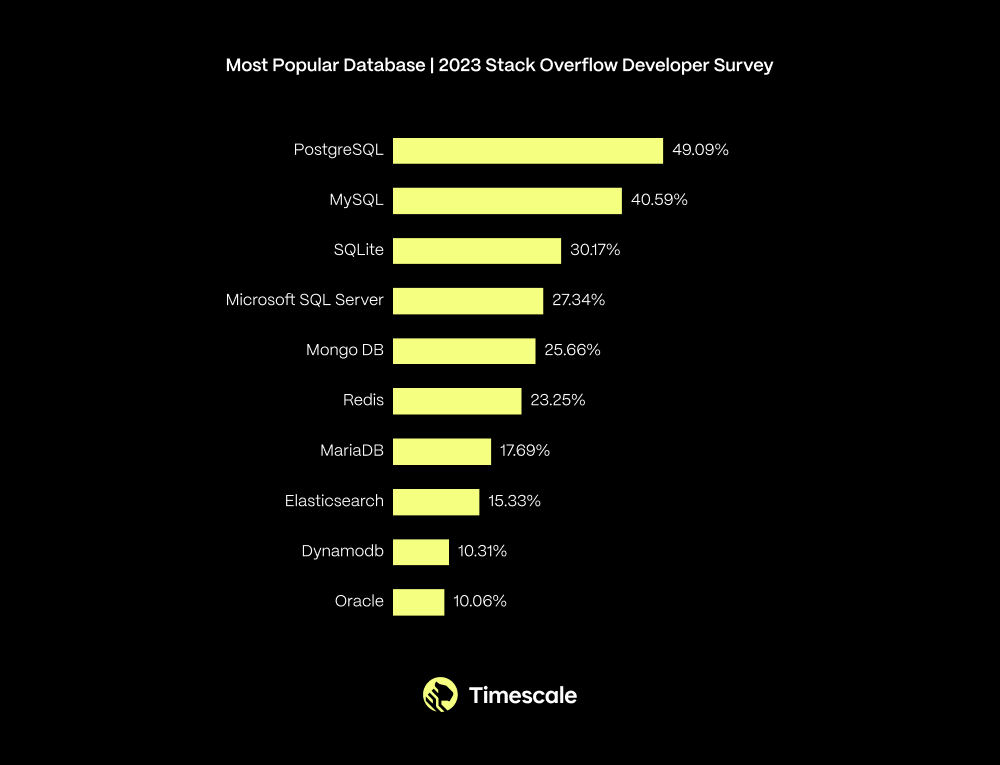
這也許可以解釋為什么去年 PostgreSQL 在專業開發者中,在最受歡迎的數據庫排行榜上,從MySQL手中奪得了榜首位置(60,369 名受訪者):
在過去一年中,你在哪些數據庫環境中進行了大量開發工作,以及在接下來的一年中你想在哪些數據庫環境中工作?超過49%的受訪者選擇了PostgreSQL。 —— 來源:StackOverflow 2023 年度用戶調研[12] 這些結果來自 2023 年的 Stack Overflow開發者調查[13]。如果縱觀過去幾年,可以看到 PostgreSQL 的使用率在過去幾年中有著穩步增長的趨勢:
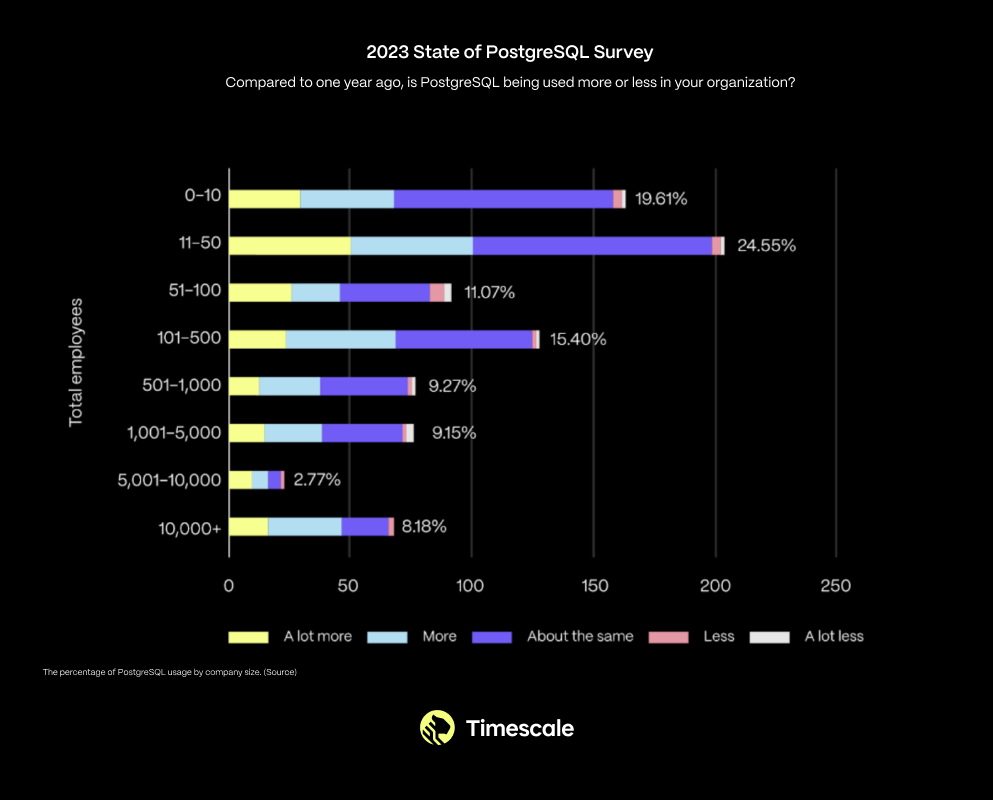
在 2020 ~ 2022 年間,根據 StackOverflow 的開發者調查顯示,PostgreSQL 是第二受歡迎的數據庫,其使用率持續上升。來源: 2020[14],2021[15],2022[16]。 This is not just a trend among small startups and hobbyists. In fact, PostgreSQL usage is increasing across organizations of all sizes: 這不僅僅是小型初創公司和業余愛好者里的趨勢。實際上,在各種規模的組織中,PostgreSQL 的使用率都在增長。
我們 Timescale 對這一趨勢并不陌生 —— 我們已經當了十年 PostgreSQL 信徒了。這也是為什么我們將自己的業務構建在 PostgreSQL 之上,為什么我們是 PostgreSQL 的頂級貢獻者之一[18],為什么我們每年舉辦 PostgreSQL 社區調研[19](上述提到),以及為什么我們支持 PostgreSQL 的 Meetup 與大會。就個人而言,我已經使用 PostgreSQL 超過 13 年了(當時我從 MySQL 切換過來)。 已經有一些博客文章討論了 如何 (How)將 PostgreSQL 用于一切問題,但還沒有討論 為什么 (Why)會這樣發生(更重要的是,這件事為什么重要?)。 直到現在。 但要理解為什么會發生這種情況,我們必須先了解一個更為基礎的趨勢,以及這個趨勢是如何改變人類現實的基本性質的。 02 一切都變成了電腦一切都變成了計算機 —— 我們的汽車、家庭、城市、農場、工廠、貨幣以及各種事物,包括我們自己,也正在變得更加數字化。我們每年都在更進一步地數字化自己的身份和行為:如何購物,如何娛樂,如何收藏藝術,如何尋找答案,如何交流和連接,以及如何表達自我。 二十二年前,這種 “無處不在的計算” 還是一個大膽的想法。那時,我是麻省理工學院人工智能實驗室的研究生,還在搞著智能環境的論文[20]。我的研究得到了麻省理工學院氧氣計劃[21]的支持,該計劃有一個崇高而大膽的目標:讓計算像我們呼吸的空氣一樣無處不在。就那時候而言,我們自己的服務器架設在一個小隔間中。 但從那以后,很多事情都變了。計算現在無處不在:在我們的桌面上,在我們的口袋里,在我們的 “云” 中,以及在我們的各種物品中。我們預見到了這些變化,但沒有預見到這些變化的二級效應: 無處不在的計算導致了無處不在的數據。隨著每一種新的計算設備的出現,我們收集了更多關于我們現實世界的信息:人類數據、機器數據、商業數據、環境數據和合成數據。這些數據正在淹沒我們的世界。 數據的洪流引發了數據庫的寒武紀大爆炸。所有這些新的數據源需要新的存儲地點。二十年前,可能只有五種可行的數據庫選項。而如今,有數百種,大多數都是針對特定的數據而特別設計的,且每個月都在涌現新的數據庫。 更多的數據和數據庫導致了更多的軟件復雜性。正確選擇適合你軟件工作負載的數據庫已不再簡單。相反,開發者被迫拼湊復雜的架構,這可能包括:關系數據庫(因其可靠性)、非關系數據庫(因其可伸縮性)、數據倉庫(因其分析能力)、對象存儲(因其便宜歸檔冷數據的能力)。這種架構甚至可能會有更為專業特化的組件,例如時序數據庫或向量數據庫。 更多的復雜性意味著留給構建軟件的時間越短。架構越復雜,它就越脆弱,就需要更復雜的應用邏輯,并且會拖慢開發速度,留給開發的時間就越少。復雜性不是一項優點,而是一項真正的成本。 隨著計算越來越普遍,我們的現實生活越來越與計算交織在一起。我們把計算帶入了我們的世界,也把我們自己帶入了計算的世界。我們不再僅僅有著線下的身份,而是一個線下與線上所作所為的混合體。 在這個新現實中,軟件開發者是人類的先鋒。正是我們構建了那些塑造這一新現實的軟件。 但是,開發者現在被數據淹沒,被淹沒在數據庫的復雜性中 這意味著開發者 —— 花費越來越多的時間,在管理內部架構上,而不是去塑造未來。 我們是如何走到這一步的? 第一部分:逐波遞進的計算浪潮無處不在的計算帶來了無處不在數據,這一變化并非一夜之間發生,而是在幾十年中逐波遞進: •主機/大型機 (1950 年代+)•個人計算機 (1970 年代+)•互聯網 (1990 年代+)•手機 (2000 年代+)•云計算 (2000 年代+)•物聯網 (2010 年代+) 每一波技術浪潮都使計算機變得更小、更強大且更普及。每一波也在前一波的基礎上進行構建:個人計算機是小型化的主機;互聯網是連接計算機的網絡;智能手機則是連接互聯網的更小型計算機;云計算普及了存算資源的獲取;物聯網則是將連接到云的智能手機組件,替代為其他物理設備。 但在過去二十年中,計算技術的進步不僅僅出現在物理世界中,也體現在數字世界中,反映了我們的混合現實: •社交網絡 (2000 年代+)•區塊鏈 (2010 年代+)•生成式人工智能 (2020 年代+) 每一波新的計算浪潮,我們都能從中獲取有關我們混合現實的新信息源:人類的數字殘留數據、機器數據、商業數據和合成數據。未來的浪潮將創造更多數據。所有這些數據都推動了新的技術浪潮,其中最新的是生成式人工智能,進一步塑造了我們的現實。 計算浪潮不是孤立的,而是像多米諾骨牌一樣相互影響。最初的數據涓流很快變成了數據洪流。接著,數據洪流又促使越來越多的數據庫的創建。 第二部分:數據庫持續增長所有這些新的數據來源,都需要新的地方來存儲 —— 即數據庫。 大型機從 Integrated Data Store[22](1964 年)開始,以及后來的 System R[23](1974 年) —— 第一個 SQL 數據庫。個人計算機推動了第一批商業數據庫的崛起:受 System R 啟發的 Oracle[24](1977 年);還有 DB2[25](1983 年);以及微軟對 Oracle 的回應: SQL Server[26](1989 年)。 互聯網的協作力量促進了開源軟件的崛起,包括第一個開源數據庫:MySQL[27](1995 年),PostgreSQL[28](1996 年)。智能手機推動了 SQLite[29](2000 年)的廣泛傳播。 互聯網還產生了大量數據,這導致了第一批非關系型(NoSQL)數據庫的出現:Hadoop[30](2006 年);Cassandra[31](2008 年);MongoDB[32](2009 年)。有人將這個時期稱為 “大數據” 時代。 第三部分:數據庫爆炸式增長大約在 2010 年,我們開始達到一個臨界點。在此之前,軟件應用通常依賴單一數據庫 —— 例如 Oracle、MySQL、PostgreSQL —— 選型是相對簡單的。 但 “大數據” 越來越大:物聯網帶來了機器數據的大爆炸;得益于 iPhone 和 Android,智能手機使用開始呈指數級增長,排放出了更多的人類數字 “廢氣”;云計算讓計算和存儲資源的獲取變得普及,并加劇了這些趨勢。生成式人工智能最近使這個問題更加嚴重 —— 它拉動了向量數據。 隨著被收集的數據量增長,我們看到了專用數據庫的興起:Neo4j[33] 用于圖形數據(2007 年),Redis[34] 用于基礎鍵值存儲(2009 年),InfluxDB[35] 用于時序數據(2013 年),ClickHouse[36] 用于大規模分析(2016 年),Pinecone 用于向量數據(2019 年),等等。 二十年前,可行的數據庫選項可能只有五種。如今,卻有數百種[37],它們大多專為特定用例設計,每個月都有新的數據庫出現。雖然早期數據庫已經承諾 通用的全能性,這些專用的數據庫提供了特定場景下的利弊權衡,而這些權衡是否有意義,取決于您的具體用例。 第四部分:數據庫越多,問題越多面對這種數據洪流,以及各種具有不同利弊權衡的專用數據庫,開發者別無選擇,只能拼湊復雜的架構。 這些架構通常包括一個關系數據庫(為了可靠性)、一個非關系數據庫(為了可擴展性)、一個數據倉庫(用于數據分析)、一個對象存儲(用于便宜的歸檔),甚至更專用的組件,如時間序列或向量數據庫,用于那些特定的用例。
但是,越復雜的架構就越脆弱,就需要更復雜的應用邏輯,并且會拖慢開發速度,留給開發的時間就越少。 這意味著開發者 —— 花費越來越多的時間,在管理內部架構上,而不是去塑造未來。 有更好的辦法解決這個問題。 PostgreSQL王者歸來故事在這里發生轉折,我們的主角不再是一個嶄新的數據庫,而是一個老牌數據庫,它的名字只有 核心開發者才會喜歡:PostgreSQL。 起初,PostgreSQL 在 MySQL 之后居于第二位,且與其相距甚遠。MySQL 使用起來更簡單,背后有公司支持,而且名字朗朗上口。但后來 MySQL 被 Sun Microsystems 收購(2008年),隨后又被 Oracle 收購(2009年)。在那時,很多軟件開發者原本視 MySQL 為擺脫昂貴的 Oracle 專制統治的自由軟件救星,在那時也不得不開始重新考慮使用什么數據庫。 與此同時,一個由幾家小型獨立公司贊助的分布式開發者社區,正在慢慢地讓 PostgreSQL 變得越來越好。他們默默地添加了強大的功能,例如全文檢索(2008年)、窗口函數(2009年)和 JSON 支持(2012年)。他們還通過流復制、熱備份、原地升級(2010年)、邏輯復制(2017年)等功能,使數據庫更加堅固可靠,同時勤奮地修復缺陷,并優化粗糙的邊緣場景。 PostgreSQL 已經成為一個平臺在此期間,PostgreSQL 添加的最具影響力的功能之一,是支持 擴展(Extension):可以為 PostgreSQL 添加功能的軟件模塊(2011年)。擴展讓更多開發者能夠獨立、迅速且幾乎無需協調地為 PostgreSQL 添加功能[38]。 得益于擴展機制,PostgreSQL 開始變成不僅僅是一個出色的關系型數據庫。得益于 PostGIS,它成為了一個出色的地理空間數據庫;得益于 TimescaleDB,它成為了一個出色的時間序列數據庫;+ hstore,鍵值存儲數據庫;+ AGE,圖數據庫;+ pgvector,向量數據庫。PostgreSQL 成為了一個平臺。 現在,開發者出于各種目的選用 PostgreSQL。例如為了可靠性、為了可伸縮性(替代NoSQL)、為了數據分析(替代數倉)。 大數據則何如?此時,聰明的讀者應該會問,“那么大數據呢?” —— 這是個好問題。從歷史上看,“大數據”(例如,幾百TB甚至上PB)—— 及相關的分析查詢,曾經對于 PostgreSQL 這種本身不支持水平擴展的數據庫來說,并不是合適的場景。 但這里的情況也在改變,去年十一月,我們推出了 “分層存儲[39]”,它可以自動將你的數據在磁盤和對象存儲(S3)之間進行分級存儲,實際上實現了 無限存儲表 的能力。 所以從歷史上看,雖然 “大數據” 曾經是 PostgreSQL 的短板,但很快將沒有任何工作負載是太大而處理不了的。 PostgreSQL 是答案。PostgreSQL 是我們解放自我,并構建未來的方式。 解放自我,構建未來,擁抱 PostgreSQL相比于在各種異構數據庫系統中糾結(每一種都有自己的查詢語言和怪癖!),我們可以依靠世界上功能最豐富,而且可能是最可靠的數據庫:PostgreSQL。我們可以不再耗費大量時間在基礎設施上,而將更多時間用于構建未來。 而且 PostgreSQL 還在不斷進步中。PostgreSQL 社區在不斷改進內核。而現在有更多的公司參與到 PostgreSQL 的開發中,包括那些巨無霸供應商。
同樣,也有更多創新的獨立公司圍繞著 PostgreSQL 內核開發,以改善其使用體驗:Supabase[41](2020年)正在將 PostgreSQL 打造成一個適用于網頁和移動開發者的 Firebase 替代品;Neon[42](2021年)和 Xata[43](2022年)都在實現將 PostgreSQL “伸縮至零”, 以適應間歇性 Serverless 工作負載;Tembo[44](2022年)為各種用例提供開箱即用的技術棧;Nile[45](2023年)正在使 PostgreSQL 更易于用于 SaaS 應用;還有許多其他公司。當然,還有我們,Timescale[46](2017年)。
尾聲:尤達?我們的現實世界,無論是物理的還是虛擬的,離線的還是在線的,都充滿著數據。正如尤達所說,數據環繞著我們,約束著我們。這個現實越來越多地由軟件所掌控,而這些軟件正是由我們這些開發者編寫的。
這一點值得贊嘆。特別是不久之前,在2002年,當我還是MIT的研究生時,世界曾經對軟件失去了信心。我們當時正在從互聯網泡沫破裂中復蘇。主流媒體 “IT并不重要[47]”。那時對一個軟件開發者來說,在金融行業找到一份好工作比在科技行業更容易——這也是我許多 MIT 同學所選擇的道路,我自己也是如此。 但今天,特別是在這個生成式AI的世界里,我們是塑造未來的人。我們是未來的建設者。我們應該感到驚喜。 一切都在變成計算機。這在很大程度上是一件好事:我們的汽車更安全,我們的家居環境更舒適,我們的工廠和農場更高效。我們比以往任何時候都能即時獲取更多的信息。我們彼此之間的聯系更加緊密。有時,它讓我們更健康,更幸福。 但并非總是如此。就像原力一樣,算力也有光明和黑暗的一面。越來越多的證據表明,手機和社交媒體直接導致了青少年心理疾病的全球流行[48]。我們仍在努力應對AI于合成生物學[49]的影響。當我們擁抱更強大的力量時,應該意識到這也伴隨著相應的責任。 我們掌管著用于構建未來的寶貴資源:我們的時間和精力。我們可以選擇把這些資源花在管理基礎設施上,或者全力擁抱 PostgreSQL,構建正確的未來。 我想你已經知道我們的立場了。 感謝閱讀。#Postgres4Life References
該文章在 2024/5/17 16:00:38 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886