整理常見(jiàn)的千萬(wàn)級(jí)數(shù)據(jù)分表的遷移方案
當(dāng)前位置:點(diǎn)晴教程→知識(shí)管理交流
→『 技術(shù)文檔交流 』
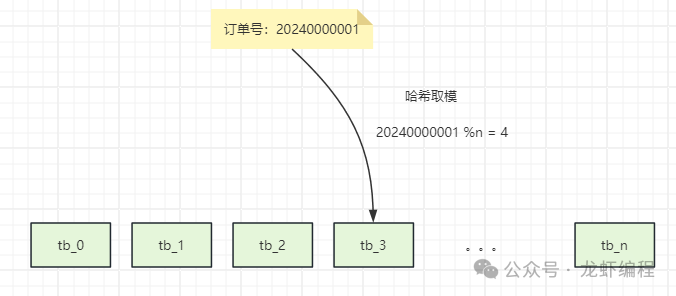
在互聯(lián)網(wǎng)業(yè)務(wù)中我們會(huì)遇到千萬(wàn)級(jí)別數(shù)據(jù)量的表需要拆分成多表存儲(chǔ),或者底層的數(shù)據(jù)存儲(chǔ)介質(zhì)的變更等原因都需要做數(shù)據(jù)的遷移,今天我們來(lái)聊聊數(shù)據(jù)的遷移方案。 1、數(shù)據(jù)的遷移策略 假設(shè)現(xiàn)在又一張千萬(wàn)級(jí)別的訂單明細(xì)表,我們需要拆分成多張子表存儲(chǔ),那么我們按照什么規(guī)則來(lái)將訂單的明細(xì)放入子表中呢? (1)哈希取模方式 訂單明細(xì)中可以選擇訂單id作為key進(jìn)行哈希取模來(lái)確定數(shù)據(jù)應(yīng)該存儲(chǔ)在哪個(gè)子表中,如下所示:
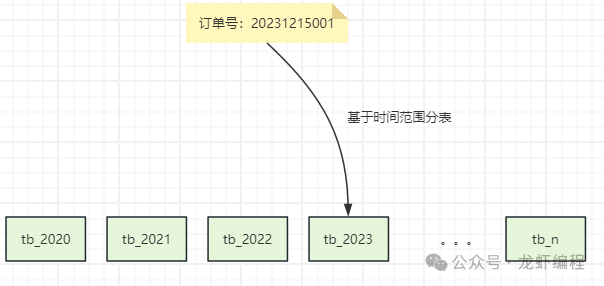
在具體選擇哪個(gè)字段為key的時(shí)候,我們能需要根據(jù)實(shí)際的業(yè)務(wù)中哪個(gè)字段的查詢(xún)最為頻繁,目的是盡量減少跨表查詢(xún)。常見(jiàn)的key可以選擇如訂單id、用戶(hù)id等等字段,采用這些字段作為分表的key,可以避免跨表查詢(xún)的問(wèn)題。 (2)基于范圍分表 首先需要確定一個(gè)合適的范圍來(lái)進(jìn)行數(shù)據(jù)遷移,常見(jiàn)的方案又基于時(shí)間范圍或基于id范圍進(jìn)行分表遷移。 基于時(shí)間分表遷移是根據(jù)時(shí)間范圍(如同一年的數(shù)據(jù)放在一個(gè)表)將數(shù)據(jù)劃分出來(lái),如下所示:
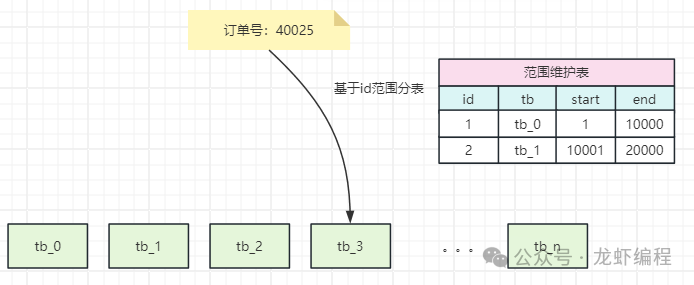
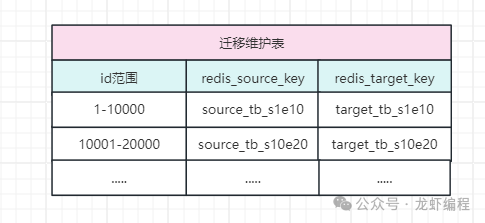
基于id范圍進(jìn)行數(shù)據(jù)遷移的方案是維護(hù)一張id訪(fǎng)問(wèn)表,然后將指定的id范圍放入某張表中,如下所示:
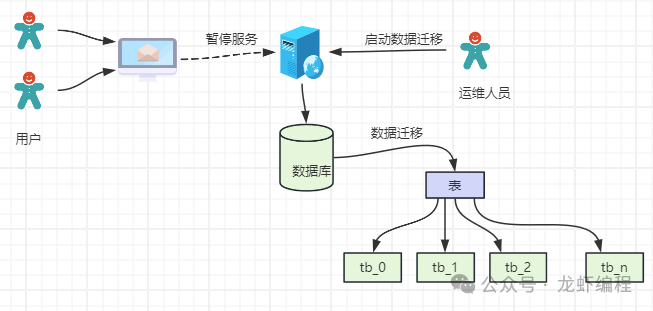
具體要用哪種遷移數(shù)據(jù)的策略要根據(jù)具體的業(yè)務(wù)場(chǎng)景,主要是基于性能、可維護(hù)性等方面考慮,最后再確定遷移的策略。 2、數(shù)據(jù)的遷移方案 2.1 停機(jī)遷移 停機(jī)遷移是一種直接且粗暴的方法,停機(jī)遷移會(huì)影響用戶(hù)的正常訪(fǎng)問(wèn),所以通常會(huì)提前給用戶(hù)一個(gè)友好的通知,如下是停機(jī)遷移的圖:
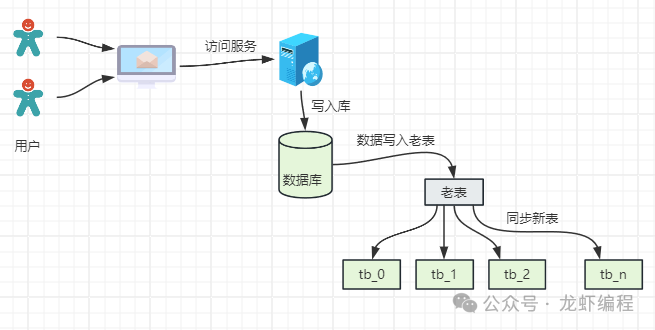
為了降低遷移過(guò)程中帶來(lái)的影響,一般都是選在凌晨進(jìn)行數(shù)據(jù)的遷移,這樣盡量將風(fēng)險(xiǎn)降到最小。許多游戲公司的服務(wù)器升級(jí),游戲分區(qū)與合區(qū),都可能會(huì)采用類(lèi)似的方案。 2.2 雙寫(xiě)策略 雙寫(xiě)策略是繼續(xù)向老表寫(xiě)入數(shù)據(jù),同時(shí)再根據(jù)分表策略把數(shù)據(jù)寫(xiě)入到新的分表中,并記錄開(kāi)始同步新表數(shù)據(jù)的時(shí)間,如下圖所示:
為了保證數(shù)據(jù)雙寫(xiě)一致性,我們需要使用定時(shí)任務(wù)對(duì)新舊表中的數(shù)據(jù)進(jìn)行對(duì)比,確保數(shù)據(jù)寫(xiě)入無(wú)錯(cuò)誤。經(jīng)過(guò)一段時(shí)間的雙寫(xiě)之后,如果沒(méi)有任何的問(wèn)題,基于最早同步的時(shí)間點(diǎn)把原始表之前的數(shù)據(jù)遷移到新表。
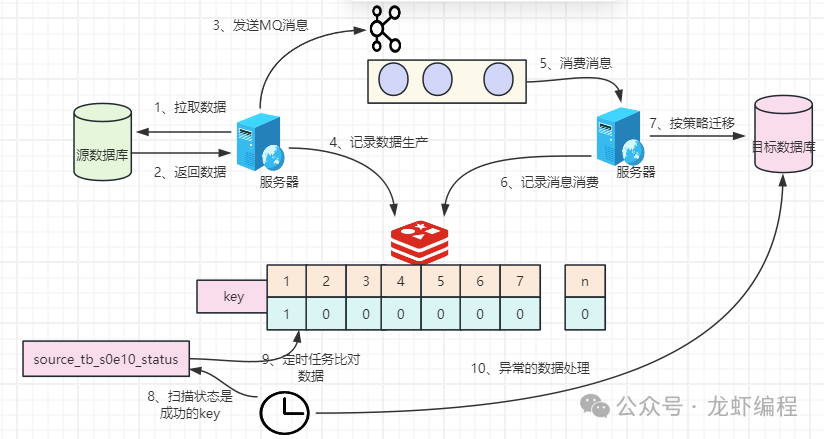
2.3 MQ+Redis實(shí)現(xiàn)數(shù)據(jù)的遷移 使用MQ+Redis做數(shù)據(jù)遷移是一種比較平滑遷移方案,方案的流程圖如下所示:
(1)制定遷移方案
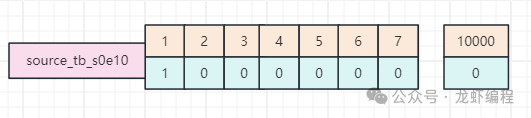
對(duì)于千萬(wàn)級(jí)別的數(shù)據(jù)量遷移,首先根據(jù)id范圍劃分的策略,如每一萬(wàn)個(gè)數(shù)據(jù)劃分成一組,然后對(duì)遷移的原始表和目標(biāo)都使用Redis的bitmap記錄每條數(shù)據(jù)的遷移情況,數(shù)據(jù)分成多少組,就使用多個(gè)Redis的key,key的命名含義如下: redis_source_key:表示遷移表中Redis的key source_tb_s1e10:表示遷移表中開(kāi)始的id從1開(kāi)始,結(jié)束的id是10000,這樣就表示id在1-10000范圍的數(shù)據(jù)。 redis_target_key:表示目標(biāo)表的Redis的key target_tb_s1e10:表示目標(biāo)表中開(kāi)始的id從1開(kāi)始,結(jié)束的id是10000,這樣就表示id在1-10000范圍的數(shù)據(jù)在目標(biāo)表中的保存情況(主要是記錄是否保存到目標(biāo)表)。 同時(shí)在Redis中也需要記錄每個(gè)分組(如1-10000)中本次遷移的開(kāi)始時(shí)間,使用key單獨(dú)記錄(如source_tb_s1e10_startTime);記錄每個(gè)分組中遷移的狀態(tài)(如遷移完成、正在遷移),使用key單獨(dú)記錄(如source_tb_s1e10_status)。 記錄分組開(kāi)始的時(shí)間和分組的遷移狀態(tài)的目的是為了定時(shí)任務(wù)做數(shù)據(jù)的補(bǔ)償。 (2)執(zhí)行遷移方案 執(zhí)行遷移方案就是將源表中的數(shù)據(jù)分組后使用MQ的方式發(fā)送到消息隊(duì)列中,然后在Redis的bitmap中記錄每條數(shù)據(jù)的遷移情況,如下所示:
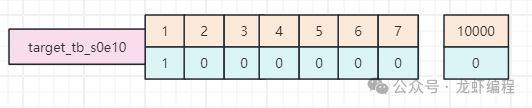
對(duì)應(yīng)的bit位上為1就表示數(shù)據(jù)已經(jīng)發(fā)送MQ中等待消費(fèi)。 在消費(fèi)端來(lái)消費(fèi)隊(duì)列中的消息,然后按照遷移數(shù)據(jù)的策略將數(shù)據(jù)落目標(biāo)表中保存下來(lái),保存成功之后在Redis的目標(biāo)key中并記錄消費(fèi)情況,如下所示:
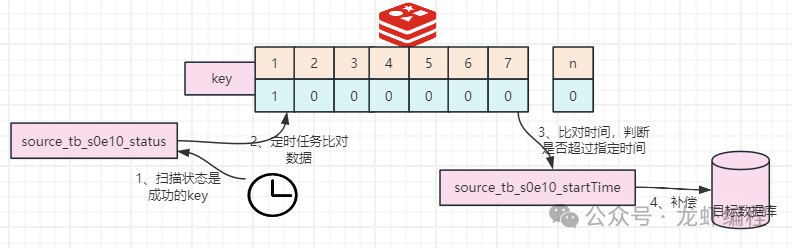
對(duì)應(yīng)的bit位上為1就表示數(shù)據(jù)已經(jīng)消費(fèi)成功。 (3)數(shù)據(jù)補(bǔ)償 為了保存數(shù)據(jù)遷移中不被遺漏,我們可以采用定時(shí)做補(bǔ)償機(jī)制,原理是通過(guò)掃描Redis中分組遷移狀態(tài)是key(如source_tb_s1e10_status)是成功狀態(tài),如下所示:
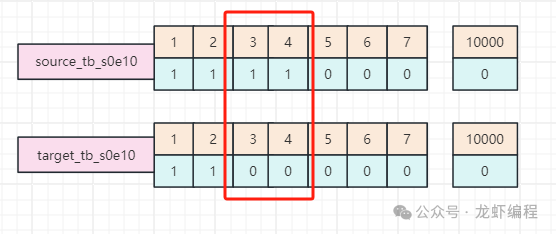
然后把遷移狀態(tài)是成功為key的生產(chǎn)端和消費(fèi)端的bitmap做異或處理,將異或結(jié)果為1的數(shù)據(jù)拿出來(lái),如下所示:
通過(guò)比對(duì)發(fā)現(xiàn)bit位的3和4位置上數(shù)據(jù)不一致(也就是生產(chǎn)端生成成功,但是消費(fèi)端消費(fèi)失敗),那么根據(jù)這個(gè)分組的開(kāi)始遷移的時(shí)間與當(dāng)前的時(shí)間做比對(duì),如過(guò)大于設(shè)置的時(shí)間(如1小時(shí)),那么我們就需要手動(dòng)的補(bǔ)償數(shù)據(jù)。 總結(jié): (1)數(shù)據(jù)的遷移策略有哈希取模、基于時(shí)間、基于id范圍等常見(jiàn)的方案。 (2)常見(jiàn)的數(shù)據(jù)遷移的方案有停機(jī)遷移、雙寫(xiě)遷移以及MQ+Redis方案遷移。 閱讀原文:原文鏈接 該文章在 2024/12/30 15:23:24 編輯過(guò) |
關(guān)鍵字查詢(xún)
相關(guān)文章
正在查詢(xún)... 晴ERP是一款針對(duì)中小制造業(yè)的專(zhuān)業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國(guó)內(nèi)大量中小企業(yè)的青睞。")
晴PMS碼頭管理系統(tǒng)主要針對(duì)港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場(chǎng)、車(chē)隊(duì)、財(cái)務(wù)費(fèi)用、相關(guān)報(bào)表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點(diǎn),圍繞調(diào)度、堆場(chǎng)作業(yè)而開(kāi)發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類(lèi)企業(yè)的高效ERP管理信息系統(tǒng)。")
晴WMS倉(cāng)儲(chǔ)管理系統(tǒng)提供了貨物產(chǎn)品管理,銷(xiāo)售管理,采購(gòu)管理,倉(cāng)儲(chǔ)管理,倉(cāng)庫(kù)管理,保質(zhì)期管理,貨位管理,庫(kù)位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號(hào)管理軟件。")
晴免費(fèi)OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時(shí)間、不限用戶(hù)的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")
|


 400 186 1886
400 186 1886
晴公司官網(wǎng)")


 ?
?