SQL Server 數據庫執行計劃和索引訪問原理
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
執行計劃是數據庫系統為了執行SQL查詢而生成的一種指導性的路線圖,它描述了數據庫引擎如何獲取數據、操作數據以及返回結果。執行計劃中的統計信息是指數據庫系統收集和存儲的關于表、索引、列等對象的數據分布、數據量、數據分布情況以及數據變化情況等信息。這些統計信息對于數據庫優化和查詢性能的評估都至關重要。 原本打算分開兩篇說明執行計劃與索引訪問原理。當前就簡單說明一下,不會深入執行計劃原理。建議先了解下索引的存儲原理SQL Server 數據庫索引原理 還是實踐說明更容易了解。
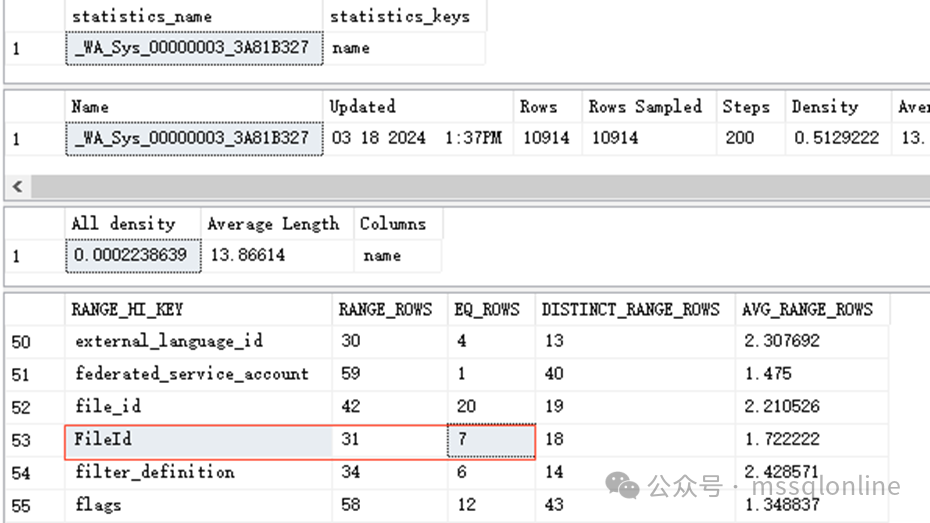
以上我創建了一張表,并執行查詢檢查執行計劃情況。 接下來就看看統計信息,sp_helpstats 可參考表有哪些統計信息,SHOW_STATISTICS 可以查看某個統計信息的分布情況。
在統計信息里面,數據將字段name的值按順序分成200份,每一份包含多個不同的值,每個值可能有多行。以上圖統計信息為例,字段name的值為“FileId”的數據有7行,字段name值在范圍大于“file_id”、小于“FileID”的數據有31行,去重之后有18行。 因此,當系統在估計查詢計劃的時候,會根據條件中不同的比較符號,估計出不同的行數。如果統計信息不準確,那么生成的執行計劃可能就不是最優的,會導致使用更大的代價。系統會觸發統計信息的更新,但對于一些大表、變化量大的表來說,觸發更新的閾值也隨之較大,這就要求我們需要定期地更新統計信息。 在 SQL Server 2016 (13.x) 前
自 SQL Server 2016 (13.x) 起
保持統計數據最新非常重要,以確保實際行和估計行盡可能緊密地對齊。對于每次插入、更新和刪除更改數據,分布都會發生變化,并且可能會扭曲估計。這些偏差可能會導致查詢計劃不夠理想并導致性能下降。設置每周更新統計作業可以幫助他們保持最新狀態。 現在我們創建一個非聚集索引,創建索引后,相關的索引統計信息也會自動生成,與字段name的統計信息沒多大差別。
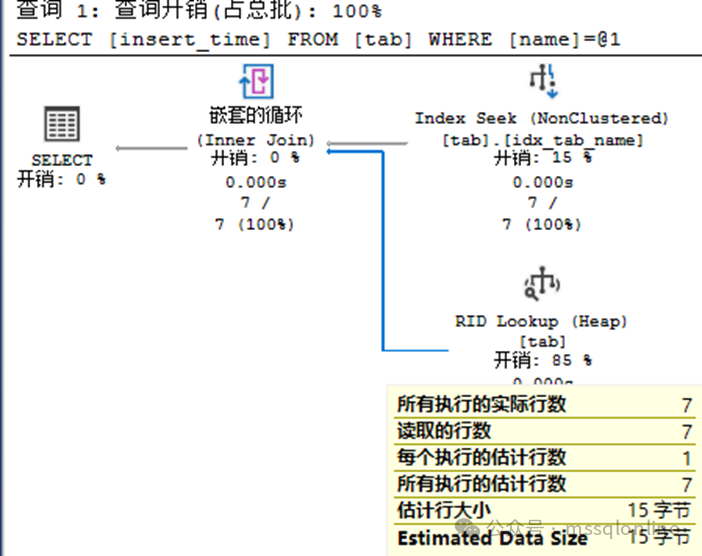
可以看到,查詢使用了該非聚集索引idx_tab_name的索引查找,但是為什么還有嵌套循環、進行 RID Lookup 呢?因為查詢是獲取所有的字段,但是索引只有字段name、以及執行堆表的 RID,通過RID進行了一次回表查詢,將其他字段值全部取出。要了解索引原理,參考文章 XXXXX。 在執行計劃的圖中,你可以點擊相應的箭頭,返回的數據量越大,箭頭也會越粗。從上圖可以分析,通過字段name查找出7行數據,每行數據都回表查詢一次,累計回表7次。要了解IO讀取情況,參考文章 XXXXX。 現在創建一個聚集索引,看看執行計劃是什么樣的。
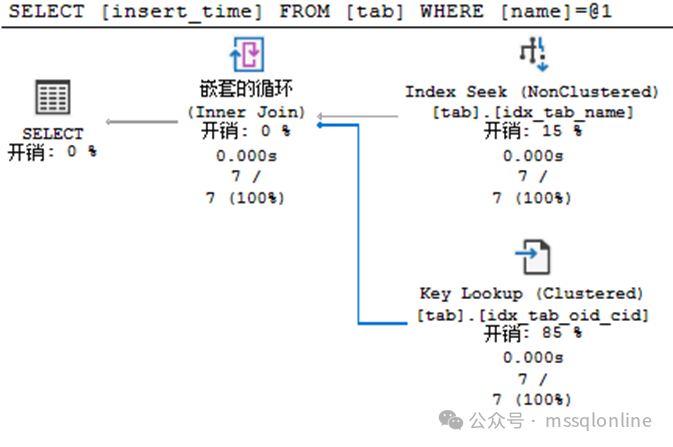
執行計劃與“RID Lookup”差別不大。創建聚集索引后,堆表轉為聚集索引表。那么非聚集索引中葉節點存儲的不在是RID,而是聚集索引的鍵列(oid,cid)。在執行計劃中,回表查找則顯示為“Key Lookup”。同樣可以看到,“Key Lookup”的開銷占比85%,在數據量較大的時候,影響會更加明顯。 那么,應該如何優化這類查詢呢?可以創建以下一種索引,復合索引或者包含列索引。
復合索引相信大家比較好理解,在索引B+Tree結構中,中間的索引節點會存在2個字段的值。而在包含列的索引中,字段insert_time只存在于葉子節點。也就是在這2個索引中,insert_time的值都包含在內。當查詢insert_time時,不需要再回表查詢了。這種優勢可以用在分頁查詢中。 如果我執行以下這個SQL,執行計劃是怎樣的呢?
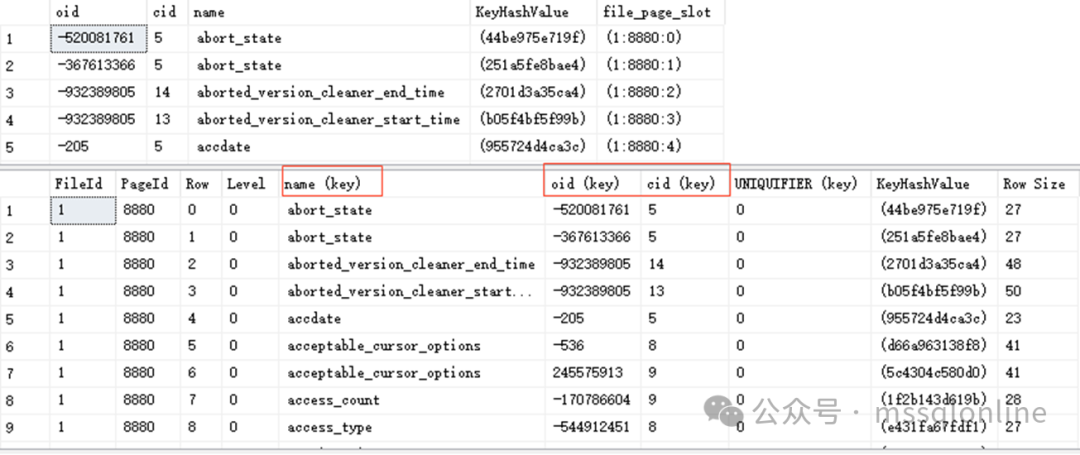
可以看到只查找了非聚集索引idx_tab_name,這是因為該非聚集索引已經包含了聚集索引鍵列,不用再回表了。如其中的一個葉節點如下。
在 SQLServer 中,成本開銷主要參考CPU開銷與IO開銷,而IO開銷的計算主要是參考頁面的讀寫情況。現在我們重新來過,驗證IO的讀取計算。
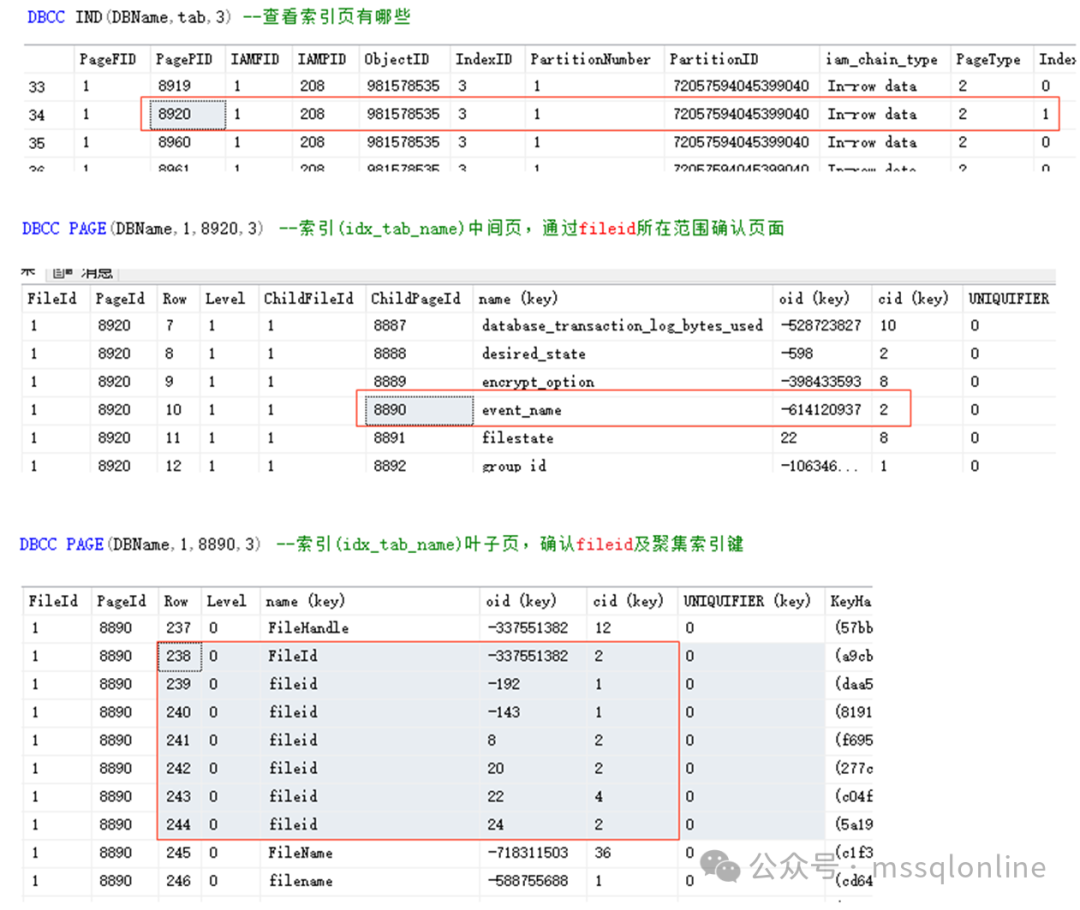
(7 行受影響) 表“tab”。掃描計數 1,邏輯讀取次數 16,物理讀取次數 0,頁面服務器讀取次數 0,預讀讀取次數 0,頁面服務器預讀讀取次數 0,LOb 邏輯讀取次數 0,LOB 邏輯讀取次數 0,LOB 頁面服務器讀取次數 0,LOB 預讀讀取次數 0,LOB 頁面服務器預讀讀取次數 0。 不管掃描聚集索引還是非聚集索引,掃描次數只有一次,不要考慮同一張表非聚集索引的嵌套循環。邏輯讀取次數為16,說明讀取了16個頁面,頁面已經緩存中。這16個頁面我們也可以猜到引擎是如何讀取的。即先通過非聚集索引讀取其子葉頁面,再回表通過聚集索引讀取其子葉。 非聚集索引idx_tab_name需要訪問3個頁面,1個IAM頁、1個索引頁、1個葉子頁面。
非聚集索引的葉子頁可以確認fileid的數據行數為7行,因為我們查詢的是字段insert_time,在非聚集索引不存在,需要回表查詢。回表就需要確認聚集索引鍵列(oid,cid)。我以第一行為例,繼續查看相關頁面。
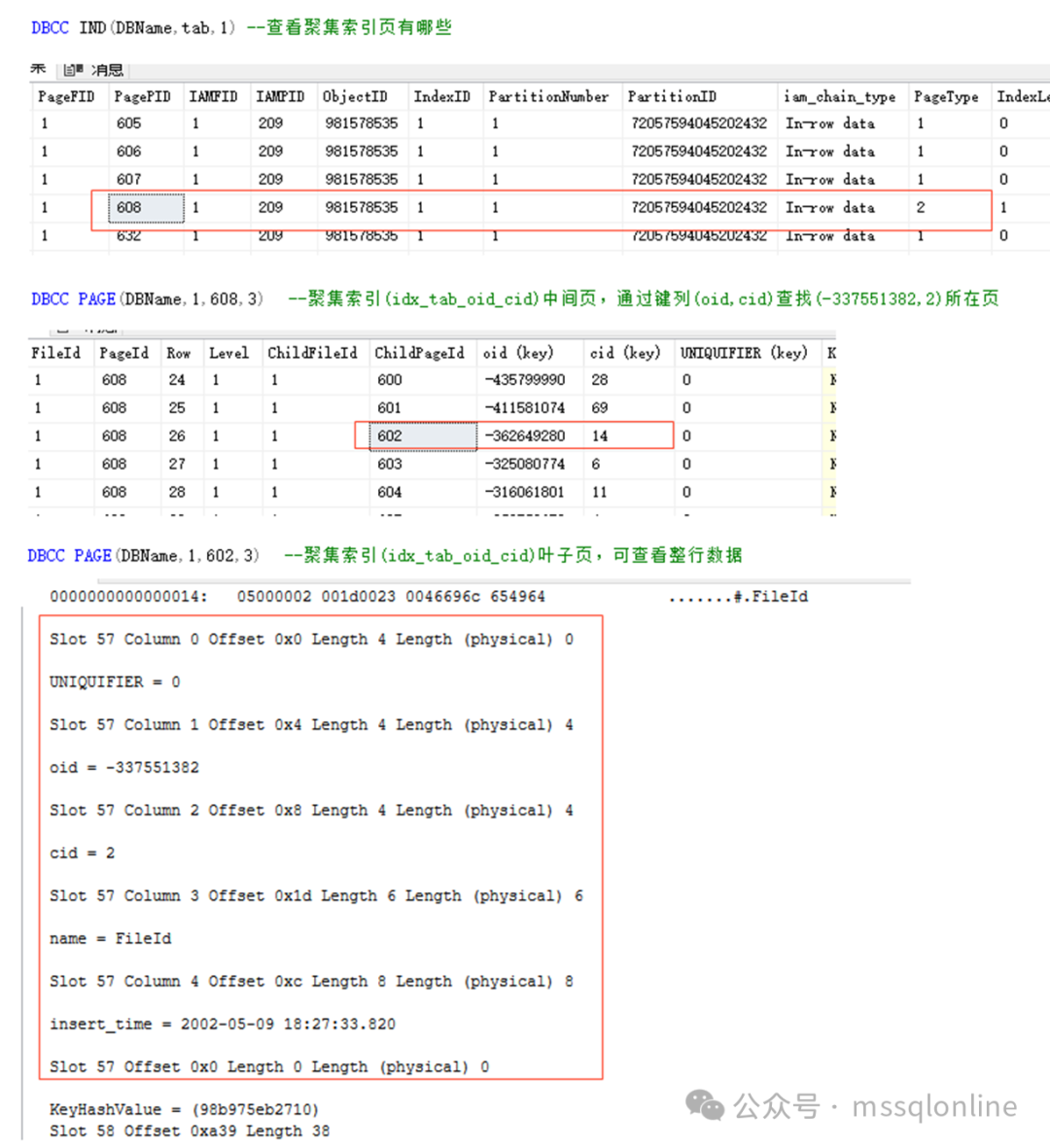
在聚集索引中,通過鍵列(oid,cid)查找(-337551382,2)所在葉子頁,需要讀取聚集索引中間索引節點1個頁面,1個葉子頁面,也就是2個頁面。
總頁面數為1 + 1 + 1*7*(1 + 1) = 16 ,即我們最開始 看到的一樣。 為了SQL有效地使用索引,我們應盡量獲取必要的字段,不要使用星號。當我們有較多表關聯的時候,條件和關聯字段應建立相關索引,盡量減少回表二次查詢。回表查詢開銷是比較大的,尤其字段較多的時候。數據是按行存儲的,當我們取某字段的時候,整行數據也會讀取到內存中,而行數據是存儲在頁面中的,這也將導致更多的IO讀取。 閱讀原文:原文鏈接 該文章在 2025/1/10 11:05:16 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886