火了整個春節的DeepSeek,他對AI產品的意義到底是什么?
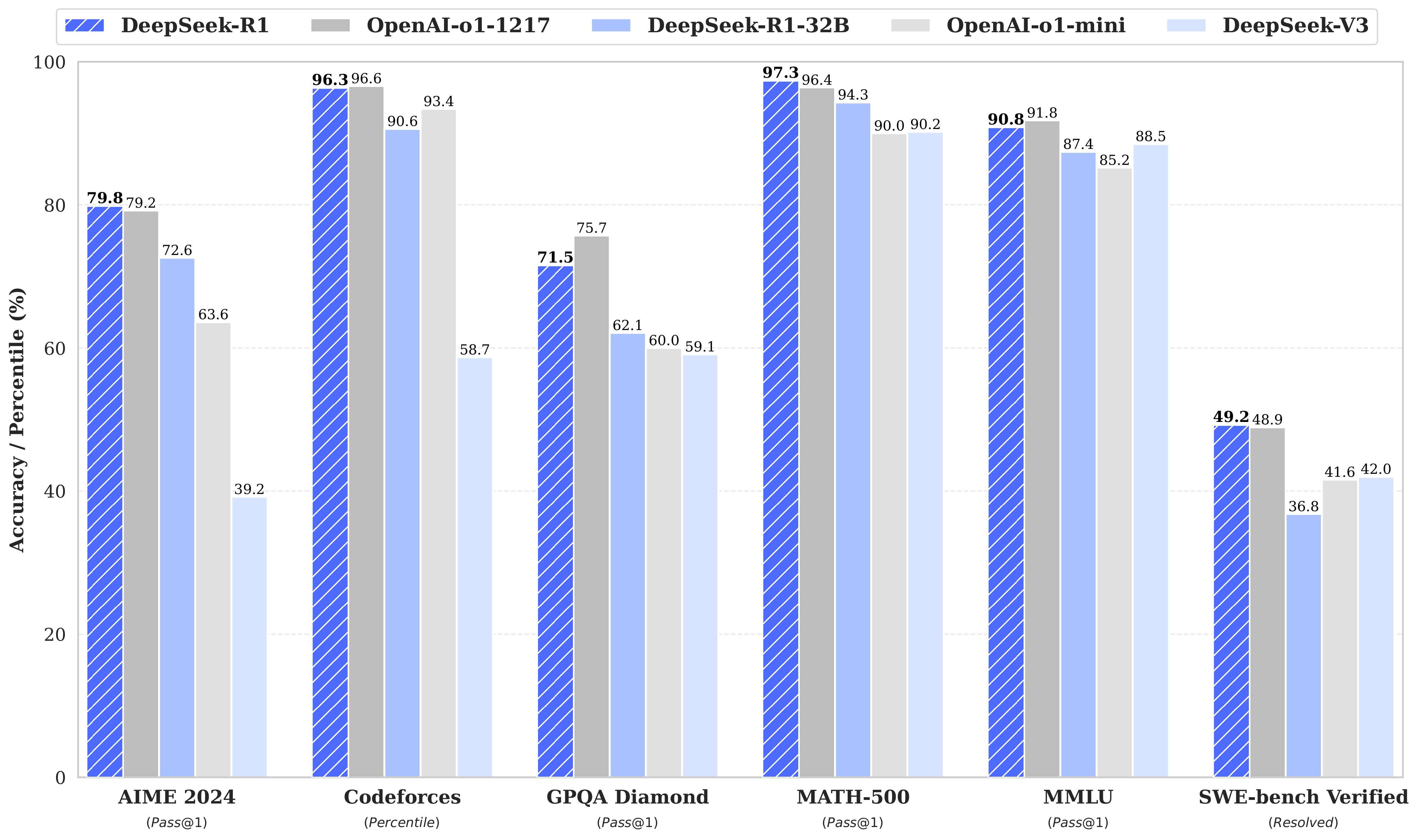
相信春節期間各位的朋友圈一定被DeepSeek“轟炸”了,就算是普通人也獲得了一些信息:國內AI取得了巨大突破。 但DeepSeek這次突破到底對一般的互聯網從業者有什么幫助,絕大多數人卻是一頭霧水。 究其原因:Attention is All You need,DeepSeek成了各大自媒體爭奪注意力的焦點,所以引起了大量的傳播和討論。 期間,我閱讀了至少100篇文章,其中包括官方很多文檔,這里的結論是:知道DeepSeek意義的博主故意不說,不懂其內涵的在不停科普,其中還摻雜了大量標題黨,所以一時魚龍混雜。 所以,今天我們整理了過去10天讀的100篇文章,得出了一些個人的認知與各位分享,如果內容有誤請您指正。 一、效果很好在我印象中DeepSeek-R是第一款直接劍指ChatGPT又取得了不錯成績的國內模型,從數據來看很硬:
所有大模型發布初期多少會有效果夸大部分,但在我親測使用的情況下:個人評價還是很高的,這其實是令人震撼的。 二、私有化部署在考慮其低成本與開源,并且開放訓練手冊(學習成本)等特性,新的機會也誕生了:
當然,研發過程中我依舊是最初的觀點:研發要著眼于半年后,依賴最強大的模型。 三、成本優勢在24年5月,DeepSeek就發布的一款名為V2的開源模型。 其性價比奇高:推理成本約等于Llama3 70B的七分之一,GPT-4 Turbo的七十分之一。 大模型最終效果一定離不開:數據(你們猜數據供應商是不是通用的?)、算法、算力三方糾纏。 區別于其他公司,DeepSeek提出的一種嶄新的MLA架構,把顯存占用降到了過去最常用的MHA架構的5%-13%。 同時,它獨創的DeepSeekMoESparse結構,也把計算量降到極致,所有這些最終促成了成本的下降。 其實,拋開效果很好這一基本元素,私有化部署與成本優勢都在其次;但在效果尚可這一前提下,成本優勢就有巨大身位領先!
四、創新更多在訓練與推理首先,我沒有讀到DeepSeek在底層模型、技術架構上的創新,更多的信息是圍繞訓練與推理是優化以及中間件的創新展開。 而DeepSeek的開源模型主要基于其自研的架構,具體細節尚未完全公開,這塊暫時無從打開。 但DeepSeek一定利用了已經開源的代碼和一些現成的語料,意味著它避免了從頭開始研發和收集數據的高昂成本。 五、模型蒸餾是關鍵而其中最為關鍵的是通過蒸餾技術,DeepSeek能夠從更大、更復雜的模型(如GPT等)中提取出核心的知識和能力,而不是重新從零開始訓練一個全新的模型。這種方法可以顯著減少需要的訓練算力和資源,降低總體成本。 此外,DeepSeek在訓練和推理過程中進行了優化,并在中間件方面進行了創新。 六、MoE的成功應用例如,DeepSeek-V3采用了混合專家(MoE)架構,擁有6710億個參數,每個詞元激活370億個參數。 而你可以將混合專家(MoE)架構 理解為 工程端的優化。 DeepSeek的MoE架構類似于一個由成百上千個領域專家小模型組成的系統。 當用戶提問時,系統首先通過意圖識別分析問題的核心內容,確定其所屬領域。 然后,通過路由系統,將請求引導至最合適的專家小模型,這些小模型會根據各自的專長生成相關答案。 若問題涉及多個領域,多個小模型可能會被激活,生成的答案隨后被一個可能稍大點的模型合并成一個完整的回應。 這種設計讓DeepSeek能夠高效處理多領域問題,保證每個領域的專家模型提供準確答案,同時通過靈活的路由系統提升整體系統的效率和準確性。 七、強化學習DeepSeek在強化學習領域的創新可能集中在優化訓練過程和提高效率方面。 通過智能的獎勵函數設計和狀態空間壓縮,DeepSeek可能減少了訓練中的計算成本,并加速了策略的收斂。 此外,結合多任務學習,DeepSeek能夠在不同任務之間共享知識和經驗,從而提升模型的訓練效率。 在實際應用中,DeepSeek還可能利用強化學習優化自動決策和資源調度,進一步增強其在復雜環境中的自適應能力。 綜上,便是我的一些簡單信息整理,有些同學很關注DeepSeek到底如何走向成功的,這里也打個比喻。 一個不恰當的比喻綜上,我們可以推理出DeepSeek成功的模糊全貌了,這里做個比喻:
AI應用側的關注點最終回歸到工程應用側,我們會更遵循拿來主義與實用主義,你如何成功對我一點都不重要,對國內的各位產研同仁來說,DeepSeek最大的意義有兩點: 第一,我們擁有了一塊國內可以媲美GPT的基座模型,這意義重大!!! 出于安全考慮,醫療、金融等多個領域是明確不允許數據外泄的,但DeepSeek的出現打破了這個魔咒 第二,DeepSeek是開源的,可以私有化部署,并且他大大降低了訓練的成本! 曾經,很多公司都在基于API做開發,其原因是首先找不到好的基座模型,其次訓練成本高昂,之前所謂的AI應用最佳實踐全部是基于成本考慮! 總結一下,站在工程應用的角度,對于基座模型的選擇只有三個考慮點:
DeepSeek對技術選型的影響最后,之前最好用的AI產品的兩個路徑是:
而DeepSeek的成功意味著更多的技術路徑有了更多的選擇,他大大加快了國內AI應用爆發的效率。 這里有幾個關鍵技術可以應用到AI產品之上,比如你要做一個AI律師,可能需要涉及到以下技術:
提示詞 VS RAG VS 微調在AI應用落地中,提示詞、RAG(檢索增強生成),以及微調是三種常見的技術路徑。它們各有特點,適合不同場景需求:
其實從底層邏輯來看,提示詞、RAG 和微調的本質都是在影響模型的輸入輸出權重,只是作用方式和影響深度不同:
三者的差異在于對模型輸入輸出權重的影響深淺:提示詞影響輕微、RAG擴展輸入、微調直接改變權重參數。 其中,RAG的底層邏輯相似,都是為優化輸入與輸出,但微調通過直接調整模型權重,從根本上改變模型能力。 DeepSeek橫空出世,對于各個公司技術路徑選擇會有深刻影響,需要提前布局。 結語從AI產品的工程應用角度來看,DeepSeek的出現為國內AI領域提供了一個全新的技術選擇,并為實際落地應用帶來了更多可能性。 作為一款具備成本優勢、開源且支持私有化部署的基礎模型,DeepSeek不僅滿足了行業對高性能、大規模模型的需求,還為醫療、金融等對數據安全和合規性要求極高的行業提供了切實可行的解決方案。 然而,盡管DeepSeek在技術上具備顯著優勢,其在實際工程應用中仍面臨諸多挑戰: 第一,行業定制化與快速部署:如何將DeepSeek的技術優勢與行業特定需求深度結合,是工程實施中的關鍵課題。 例如,在法律、醫療等領域,AI應用不僅需要高效的知識檢索與推理能力,還必須保證生成結果的精準度和可靠性。 這要求開發團隊在數據清洗、領域知識注入和模型微調等方面進行大量定制化開發與測試。 其次快速部署能力也是工程應用中的一大挑戰。 DeepSeek的私有化部署特性雖然解決了數據安全問題,但在實際落地中,如何實現從模型訓練到推理服務的無縫銜接,仍需在工程架構和工具鏈上進行優化。 并且,在線模型是會迭代的,私有化后就不能迭代了,這個怎么解決還需要思考。 第二,推理性能與成本優化:DeepSeek通過蒸餾技術和MLA架構顯著降低了訓練和推理成本,但在實際應用中,如何在不犧牲性能的情況下進一步優化推理效率,仍是技術實現中的難點。 例如,在實時性要求較高的場景(如智能客服、實時法律咨詢)中,如何通過模型壓縮、量化技術或分布式推理來提升響應速度,是工程團隊需要重點解決的問題。 此外,如何結合強化學習和混合專家(MoE)架構的優勢,實現多任務處理的高效性與準確性,尤其是在多領域聯合任務處理時,確保系統的穩定性和性能,也是工程應用中的重要考量。 第三,技術路徑的靈活選擇:在未來的應用路徑選擇上,開發者需要根據業務需求靈活運用提示詞優化、RAG技術和模型微調等手段。例如: 對于輕量級應用(如創意文案生成),提示詞工程可能是最經濟高效的選擇; 對于需要動態知識更新的場景(如醫療問答),RAG技術可以顯著提升生成內容的準確性; 對于高精度、高專業性的任務(如金融分析),模型微調則是不可或缺的手段。 開發者還需在多元化的技術框架中找到最適合自身業務的解決方案,從而提升AI技術的生產力,實現技術向實際業務場景的高效落地。 總結DeepSeek的出現為AI工程應用帶來了新的機遇,但其成功落地仍依賴于開發者對行業需求的深刻理解和對技術路徑的靈活選擇。 未來,AI產品的開發團隊需要在定制化開發、性能優化和工程生態構建等方面持續投入,才能充分發揮DeepSeek的技術優勢,推動AI技術在實際業務場景中的普及與落地。 通過不斷優化工程實現路徑,DeepSeek有望成為國內AI應用開發的核心引擎,助力各行各業實現智能化轉型。 轉自https://www.cnblogs.com/yexiaochai/p/18699686 該文章在 2025/2/7 9:28:32 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886